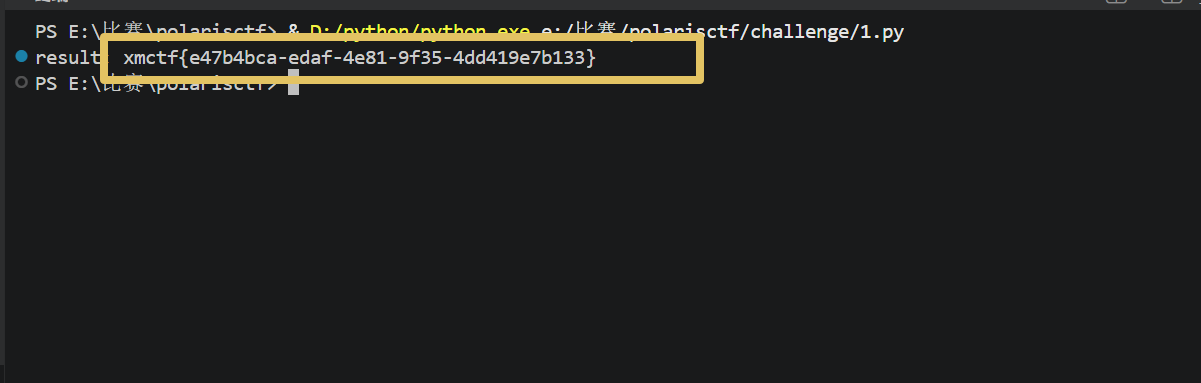
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| from PIL import Image
import cv2
import numpy as np
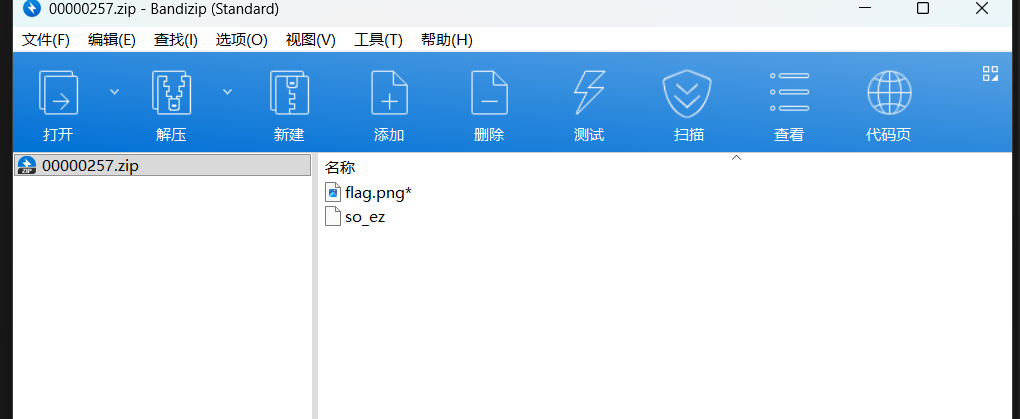
INPUT_PATH = "flag.png"
OUTPUT_PATH = "flag_fixed.png"
MODULE_SIZE = 10
OFFSET = 40
FLIPS = [(9, 0), (14, 0), (16, 0), (20, 0), (21, 0), (24, 0), (26, 0), (28, 0), (8, 1), (10, 1), (11, 1), (13, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (24, 1), (26, 1), (8, 2), (11, 2), (12, 2), (15, 2), (18, 2), (19, 2), (20, 2), (23, 2), (25, 2), (26, 2), (27, 2), (9, 3), (10, 3), (14, 3), (15, 3), (18, 3), (19, 3), (21, 3), (22, 3), (25, 3), (26, 3), (8, 4), (12, 4), (13, 4), (15, 4), (16, 4), (18, 4), (19, 4), (22, 4), (24, 4), (26, 4), (27, 4), (9, 5), (12, 5), (13, 5), (15, 5), (18, 5), (19, 5), (20, 5), (21, 5), (22, 5), (23, 5), (25, 5), (26, 5), (27, 5), (8, 7), (9, 7), (10, 7), (14, 7), (15, 7), (18, 7), (21, 7), (23, 7), (25, 7), (26, 7), (27, 7), (28, 7), (1, 8), (5, 8), (7, 8), (8, 8), (10, 8), (13, 8), (14, 8), (15, 8), (19, 8), (24, 8), (26, 8), (27, 8), (29, 8), (30, 8), (32, 8), (34, 8), (35, 8), (4, 9), (5, 9), (7, 9), (9, 9), (11, 9), (12, 9), (13, 9), (15, 9), (19, 9), (20, 9), (23, 9), (24, 9), (25, 9), (29, 9), (30, 9), (34, 9), (1, 10), (2, 10), (5, 10), (7, 10), (8, 10), (9, 10), (11, 10), (13, 10), (14, 10), (16, 10), (17, 10), (18, 10), (19, 10), (20, 10), (21, 10), (23, 10), (24, 10), (28, 10), (29, 10), (30, 10), (32, 10), (33, 10), (34, 10), (35, 10), (36, 10), (0, 11), (3, 11), (4, 11), (5, 11), (10, 11), (11, 11), (15, 11), (16, 11), (17, 11), (18, 11), (20, 11), (21, 11), (22, 11), (23, 11), (25, 11), (27, 11), (28, 11), (29, 11), (31, 11), (33, 11), (34, 11), (36, 11), (0, 12), (1, 12), (2, 12), (4, 12), (7, 12), (8, 12), (12, 12), (13, 12), (14, 12), (15, 12), (17, 12), (19, 12), (22, 12), (26, 12), (27, 12), (33, 12), (34, 12), (35, 12), (0, 13), (1, 13), (2, 13), (3, 13), (4, 13), (7, 13), (11, 13), (14, 13), (16, 13), (17, 13), (26, 13), (29, 13), (30, 13), (32, 13), (33, 13), (2, 14), (4, 14), (5, 14), (7, 14), (10, 14), (12, 14), (13, 14), (16, 14), (18, 14), (19, 14), (21, 14), (22, 14), (26, 14), (32, 14), (33, 14), (36, 14), (0, 15), (3, 15), (4, 15), (7, 15), (10, 15), (11, 15), (12, 15), (13, 15), (15, 15), (16, 15), (17, 15), (18, 15), (19, 15), (20, 15), (22, 15), (23, 15), (26, 15), (28, 15), (29, 15), (30, 15), (32, 15), (33, 15), (35, 15), (36, 15), (3, 16), (7, 16), (11, 16), (12, 16), (13, 16), (14, 16), (17, 16), (18, 16), (23, 16), (24, 16), (25, 16), (29, 16), (32, 16), (33, 16), (36, 16), (0, 17), (1, 17), (5, 17), (7, 17), (8, 17), (11, 17), (12, 17), (14, 17), (15, 17), (17, 17), (19, 17), (24, 17), (25, 17), (29, 17), (30, 17), (31, 17), (32, 17), (33, 17), (34, 17), (35, 17), (3, 18), (4, 18), (7, 18), (8, 18), (11, 18), (18, 18), (20, 18), (21, 18), (22, 18), (25, 18), (26, 18), (28, 18), (30, 18), (33, 18), (1, 19), (9, 19), (10, 19), (11, 19), (13, 19), (14, 19), (16, 19), (17, 19), (19, 19), (20, 19), (21, 19), (24, 19), (25, 19), (26, 19), (27, 19), (28, 19), (29, 19), (30, 19), (31, 19), (33, 19), (36, 19), (1, 20), (2, 20), (8, 20), (10, 20), (15, 20), (17, 20), (19, 20), (20, 20), (21, 20), (24, 20), (26, 20), (27, 20), (28, 20), (30, 20), (31, 20), (32, 20), (34, 20), (35, 20), (36, 20), (1, 21), (2, 21), (4, 21), (5, 21), (7, 21), (8, 21), (9, 21), (12, 21), (13, 21), (21, 21), (23, 21), (24, 21), (25, 21), (26, 21), (28, 21), (29, 21), (30, 21), (31, 21), (33, 21), (34, 21), (35, 21), (36, 21), (1, 22), (2, 22), (3, 22), (5, 22), (8, 22), (10, 22), (11, 22), (16, 22), (20, 22), (22, 22), (23, 22), (24, 22), (25, 22), (30, 22), (31, 22), (32, 22), (34, 22), (35, 22), (36, 22), (2, 23), (4, 23), (11, 23), (15, 23), (18, 23), (21, 23), (22, 23), (23, 23), (25, 23), (32, 23), (33, 23), (34, 23), (1, 24), (4, 24), (7, 24), (9, 24), (10, 24), (13, 24), (14, 24), (15, 24), (16, 24), (18, 24), (21, 24), (22, 24), (25, 24), (26, 24), (27, 24), (28, 24), (32, 24), (35, 24), (36, 24), (5, 25), (8, 25), (14, 25), (15, 25), (17, 25), (18, 25), (19, 25), (21, 25), (25, 25), (26, 25), (29, 25), (30, 25), (32, 25), (33, 25), (34, 25), (35, 25), (0, 26), (1, 26), (2, 26), (3, 26), (5, 26), (9, 26), (10, 26), (12, 26), (14, 26), (18, 26), (21, 26), (23, 26), (32, 26), (33, 26), (34, 26), (36, 26), (0, 27), (1, 27), (4, 27), (7, 27), (9, 27), (11, 27), (13, 27), (14, 27), (15, 27), (17, 27), (18, 27), (20, 27), (21, 27), (22, 27), (23, 27), (25, 27), (26, 27), (28, 27), (29, 27), (30, 27), (33, 27), (36, 27), (0, 28), (2, 28), (5, 28), (8, 28), (9, 28), (10, 28), (12, 28), (14, 28), (19, 28), (21, 28), (22, 28), (27, 28), (33, 28), (35, 28), (9, 29), (10, 29), (12, 29), (17, 29), (18, 29), (22, 29), (23, 29), (24, 29), (33, 29), (35, 29), (8, 30), (9, 30), (10, 30), (13, 30), (14, 30), (15, 30), (20, 30), (24, 30), (25, 30), (26, 30), (27, 30), (8, 31), (10, 31), (14, 31), (15, 31), (17, 31), (19, 31), (20, 31), (22, 31), (23, 31), (24, 31), (27, 31), (33, 31), (12, 32), (13, 32), (15, 32), (16, 32), (18, 32), (19, 32), (20, 32), (22, 32), (23, 32), (35, 32), (9, 33), (10, 33), (13, 33), (15, 33), (16, 33), (17, 33), (18, 33), (19, 33), (21, 33), (22, 33), (25, 33), (26, 33), (27, 33), (30, 33), (32, 33), (33, 33), (34, 33), (35, 33), (36, 33), (9, 34), (13, 34), (14, 34), (15, 34), (18, 34), (21, 34), (22, 34), (23, 34), (25, 34), (27, 34), (28, 34), (31, 34), (33, 34), (35, 34), (36, 34), (8, 35), (11, 35), (14, 35), (17, 35), (19, 35), (21, 35), (25, 35), (27, 35), (30, 35), (32, 35), (33, 35), (35, 35), (10, 36), (11, 36), (12, 36), (13, 36), (16, 36), (17, 36), (26, 36), (29, 36), (30, 36), (31, 36), (32, 36), (33, 36), (34, 36)]
img = Image.open(INPUT_PATH).convert("L")
arr = np.array(img)
for x, y in FLIPS:
y0 = OFFSET + y * MODULE_SIZE
y1 = y0 + MODULE_SIZE
x0 = OFFSET + x * MODULE_SIZE
x1 = x0 + MODULE_SIZE
block = arr[y0:y1, x0:x1]
arr[y0:y1, x0:x1] = 255 - block
fixed = Image.fromarray(arr)
fixed.save(OUTPUT_PATH)
print(f"saved to {OUTPUT_PATH}")
qr = cv2.QRCodeDetector()
value, points, _ = qr.detectAndDecode(arr)
print("decoded:", value)
|